The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
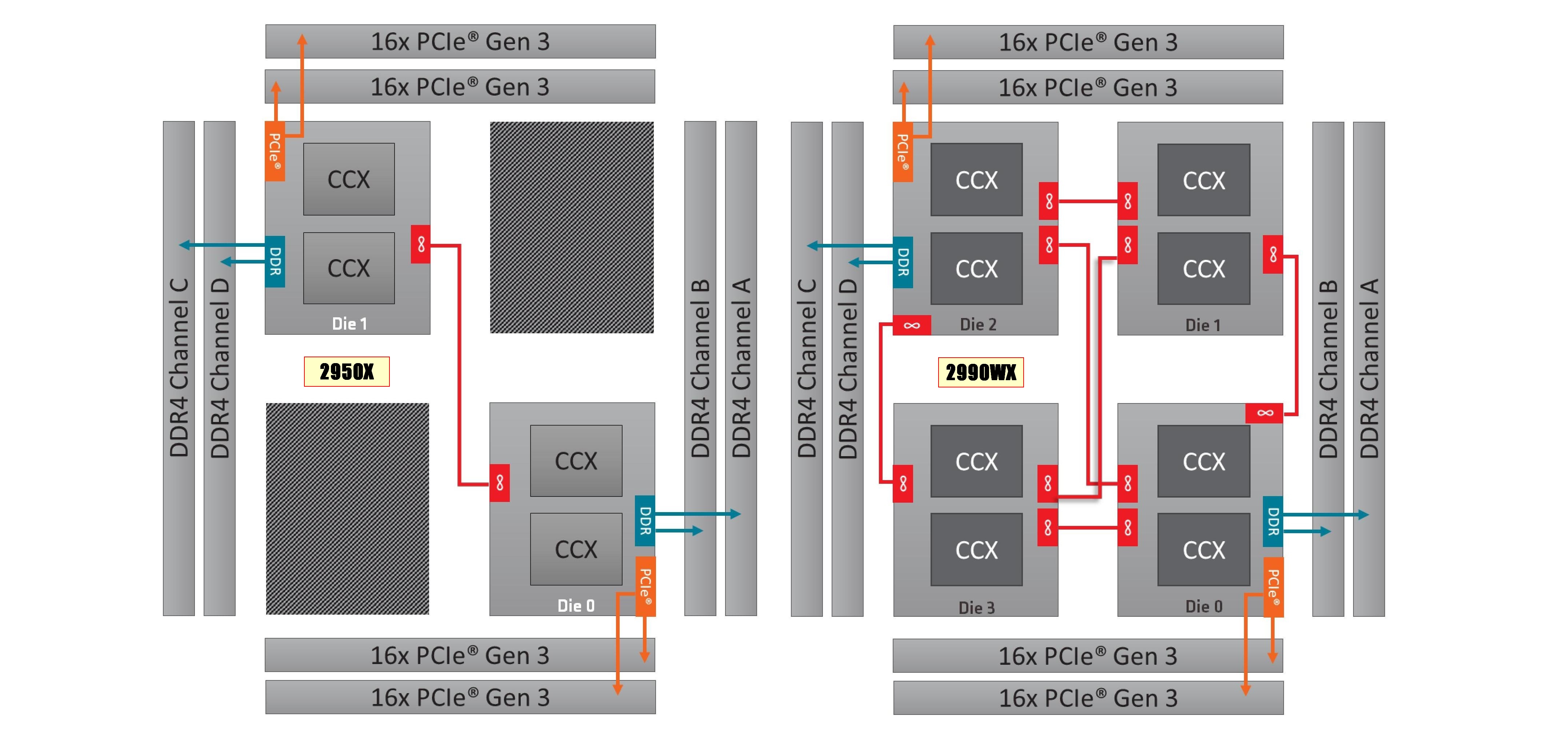
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
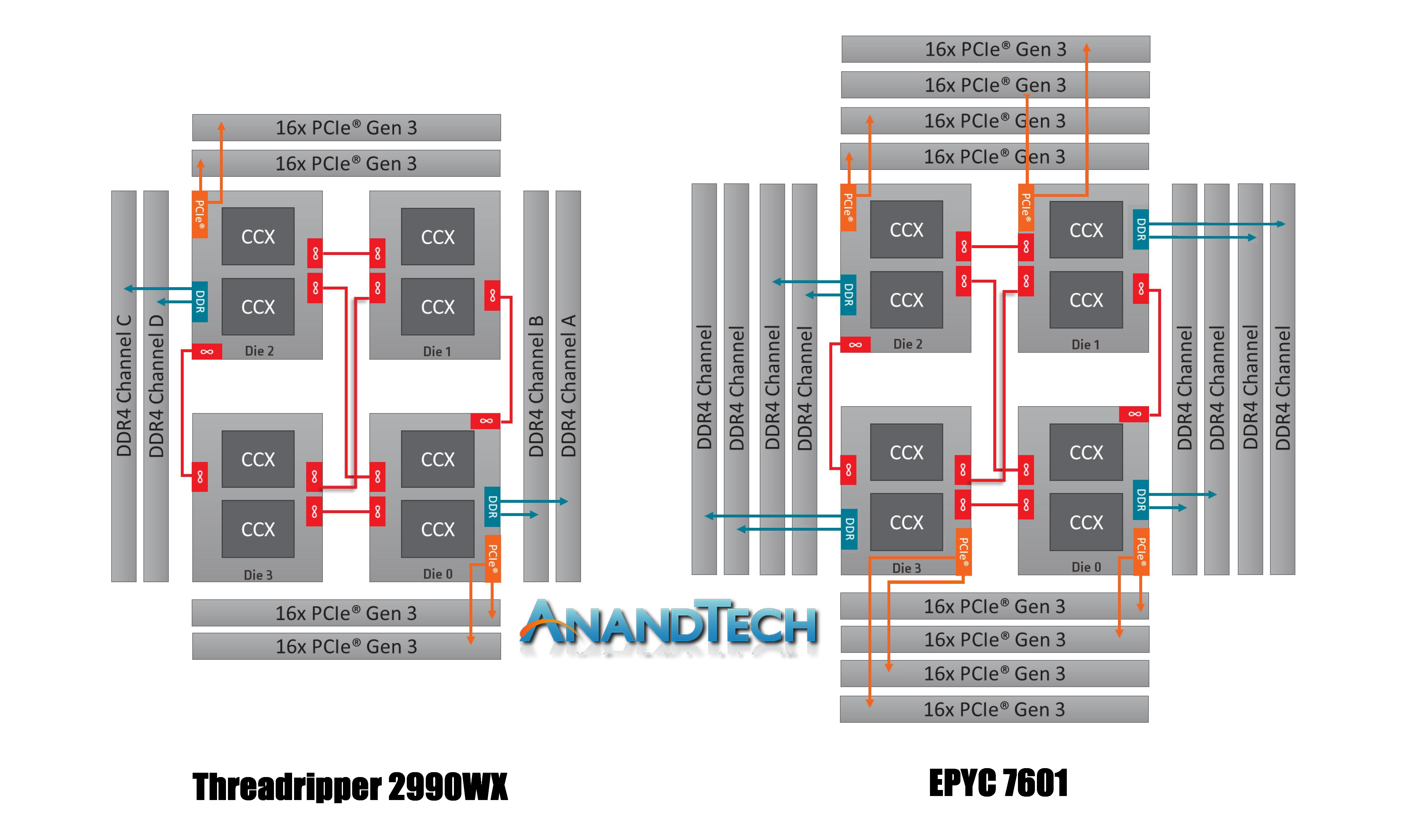
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
eva02langley - Tuesday, August 14, 2018 - link
You don't get it, it is a proof of concept and a disruptive tactic to get notice for people to consider AMD in the future... and it works perfectly.KAlmquist - Thursday, August 16, 2018 - link
That's what I meant by “bragging rights.”eva02langley - Thursday, August 16, 2018 - link
You are missing the business standpoint, the stakeholders and the proof of concept.Nvidia is surfing on AI, however the only thing they did so far is selling GPU during a mining craze, however people drink their coolaid and the investors are all over them. The hangover is going to be hard.
Lolimaster - Monday, August 13, 2018 - link
If you're a content creator the Threaripper 2950X is you bitch, period.MrSpadge - Tuesday, August 14, 2018 - link
Ian, does the power consumption of uncore (IF + memory controller) scale with IF + memory controller frequency? I would expect so. And if not: maybe AMD is missing on huge possible power savings at lower frequencies. Not sure if overall efficiency could benefit from that, though, as performance and power would simulataneously regress.dynamis31 - Tuesday, August 14, 2018 - link
It's not all silicon !Windows OS and applications running on that OS may also be software optimised for more 2990WX workloads as you can see below :
https://www.phoronix.com/forums/forum/phoronix/lat...
dmayo - Tuesday, August 14, 2018 - link
Meanwhile, in Linux 2990WX destroyed competition.https://www.phoronix.com/scan.php?page=article&...
https://www.phoronix.com/scan.php?page=article&...
eva02langley - Tuesday, August 14, 2018 - link
I am beginning to ask myself if this is related to Windows. Or maybe the bench suites reliability toward such a unique product.But yeah, these results are insane.
MrSpadge - Tuesday, August 14, 2018 - link
Crazy results, indeed. And quite believable, considering how well the 16 core TR fares in comparison in many windows benches. I suspect the scheduler is not yet tuned for the new architecture with 2 different NUMA levels.And for at least parts of the benchmarks I suspect something a lot less technical is happening: Phoronix can only bench cross-platform software for this comparison. However, hardly any Windows programmer is regularly building Linux versions. That leaves just another option: Linux programs which also got a Windows build. And considering how downright hostile Linux fans can be towards Windows and anything Microsoft-related, I wouldn't be surprised if the tuning going into these compilations was far from ideal. Some of these guys really enjoy shouting out loud that they don't have access to any Windows machine to test their build (which they only did to stop the requests flooding their inbox) and to shove down their users throat that Windows is a second class citizen in their world. This point is reinforced by the wierd names of many of the benchmarks - except 7-zip, is anyone using those programs?
GreenReaper - Wednesday, August 15, 2018 - link
Most aren't dedicated benchmarks, they're useful programs being run as such:* x264 powers most CPU-based H.264/AVC video encoding. Steam uses it, for example.
* GraphicsMagick is a fork of ImageMagick, one of which is used in a large number of websites (probably including this one) for processing images.
* FFmpeg is for audio and video processing.
* Blender is a popular open-source rendering tool.
* Minion is for constraint-solving (e.g. the four-colour map problem).
Many aren't the kind of things you'd run on a regular desktop - but a workstation, sure. They are CPU-intensive parallel tasks which scale - or you hope will scale - with threads.