The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
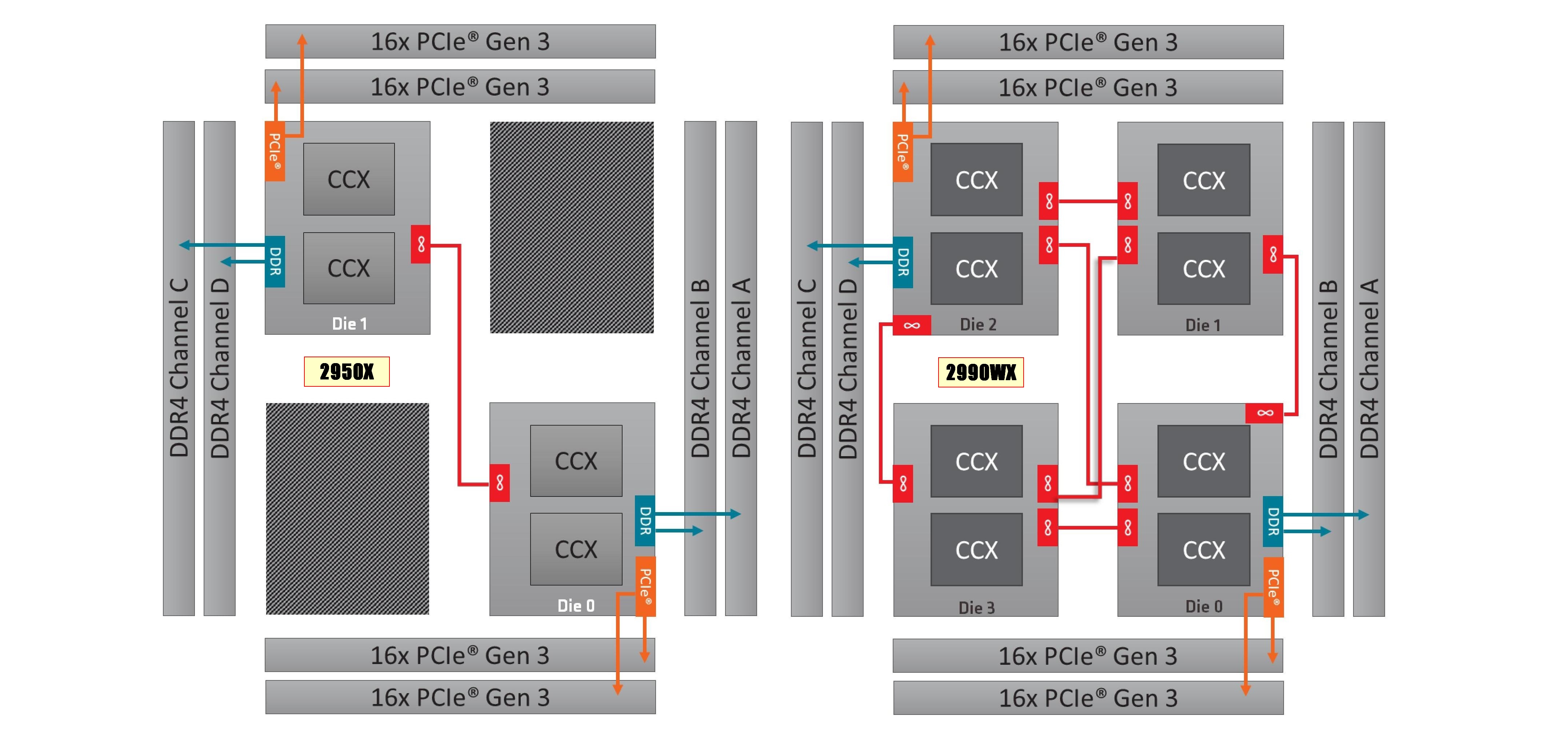
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
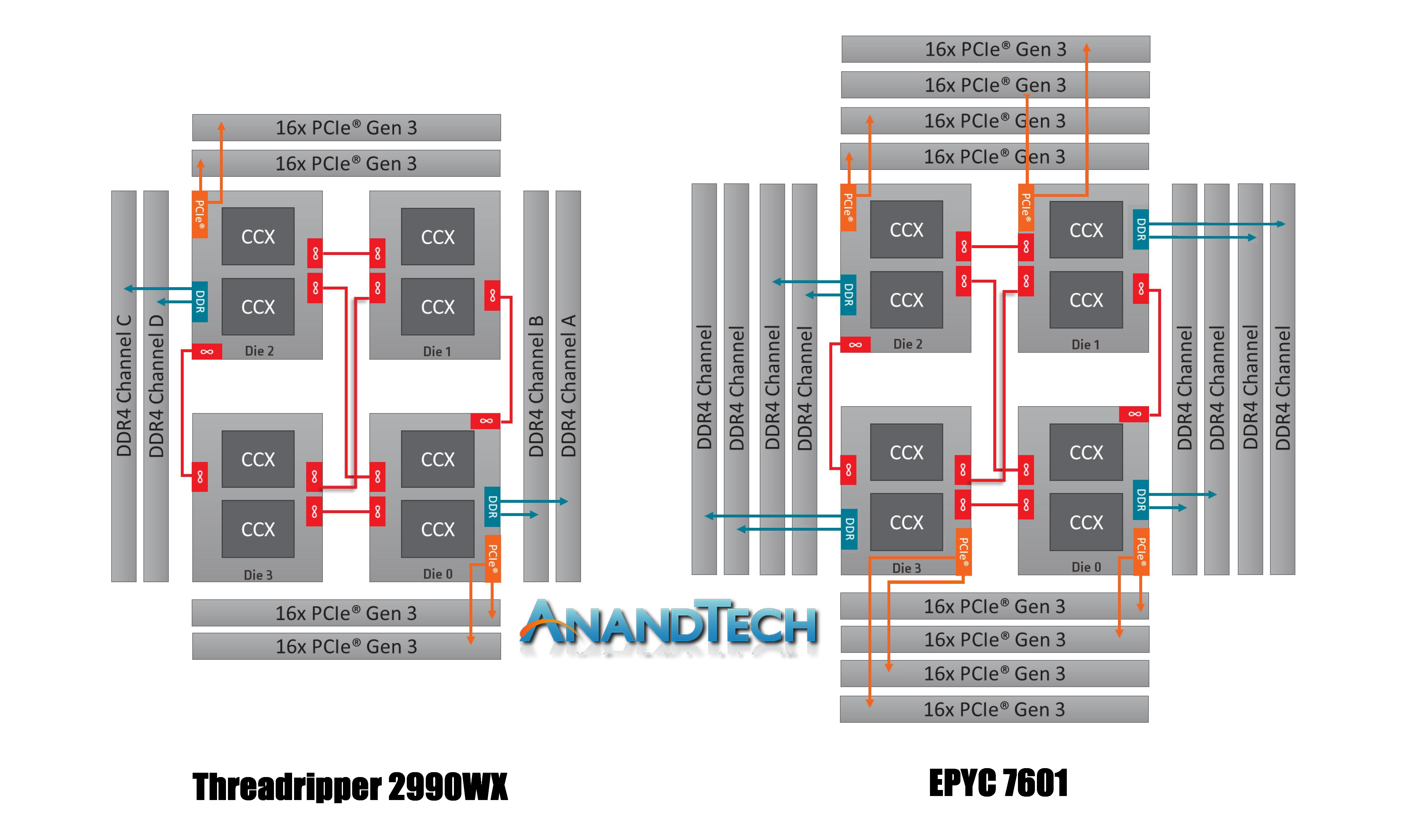
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
3DVagabond - Wednesday, August 15, 2018 - link
When did you switch to this new benchmark suite?Lord of the Bored - Wednesday, August 15, 2018 - link
Still writing...mukiex - Friday, August 17, 2018 - link
Looks like it's no longer a problem! They deleted all those pages.GreenReaper - Saturday, August 18, 2018 - link
They're back again now.abufrejoval - Wednesday, August 15, 2018 - link
Separating CPU (and GPU) cores from their memory clearly doesn't seem sustainable going forward.That's why I find the custom chip did for the chinese console so interesting: If they did an HBM variant, perhaps another with 16 or even 32GB per SoC, they'd use the IF mostly for IPC/non-local memory access and the chance of using GPGPU compute for truly parallel algorithms would be much bigger as the latency of context switches between CPU and GPU code would be minimal with both using the same physical memory space.
They might still put ordinary RAM or NV-RAM somewhere to the side as secondary storage, so it looks a little like Knights Landing.
IF interconnects might be a little longer, really long when you scale beyond what you can fit on a single board and probably something where optical interconnects would be better (once you got them...)
I keep having visions of plenty of such 4x boards swimming immersed in a tank of this "mineral oil" stuff that evidently has little to do with oil but allows so much more density and could run around those chips 'naked'.
Alaa - Wednesday, August 15, 2018 - link
I do not think that testing only a single tool at a time is a good benchmark for such high core count architecture. These cores need concurrent workloads to showcase their real power.csell - Thursday, August 16, 2018 - link
Can somebody please tell me the difference between the ASUS ROG Zenith Extreme motherboard rev 2 used here and the old ASUS ROG Zenith Extreme motherboard. I can't find any information about the rev 2 somewhere else?UnNameless - Friday, August 17, 2018 - link
I also want to know that. I have the "rev 1" Asus rog zenith extreme and can't find any difference.spikespiegal - Friday, August 17, 2018 - link
Companies buy PC's to run applications and don't care about memory timing, CPU's, clock speed or any other MB architecture. They only care about the box on the desk to run applications and ROI, as they should. AMD has historically only made a dent in the low end desktop market because Intel has this funny habit of not letting chip prices depreciate much below $200. AMD does, so they occupy the discount desktop market because when you buy 10,000 general purpose workstations saving $120 per box is a big chunk of change.I'm looking at the benchmark tests and all I'm seeing is the AMD chips doing well in mindless rendering and other synthetic desktop tasks no one outside multimedia would care about. The i7 holds it's own in too many complex application tests, which proves that once again per core efficacy is all that matters and AMD can't alter the reality of this. Where is the VMware host / mixed guest application benchmark consisting of Exchange, SQL, RDS, file services, AD and other? You know, those things that run corporate commerce and favor high core efficacy? Nobody runs bare metal servers anymore, and nobody reputable builds their own servers.
Dragonrider - Friday, August 17, 2018 - link
Ian, are you going to test PBO performance with these processors (I know, it was probably not practical while you were on the road)? Some questions popped up in my mind. Can PBO be activated when the processor in partial mode (i.e. 1/2 mode or game mode in the case of the 2990)? Also What does the power consumption and performance look like in those partial modes for different application sets with and without PBO? I know that represents a lot of testing, but on the surface, the 2990 looks like it could be a really nice all-round processor if one were willing to do some mode switching. It seems like it should perform pretty close to the 2950 in game mode and 1/2 mode and you have already established that it is a rendering beast in full mode. Bottom line, I think the testing that has been published so far only scratches the surface of what this processor may be capable of.