The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
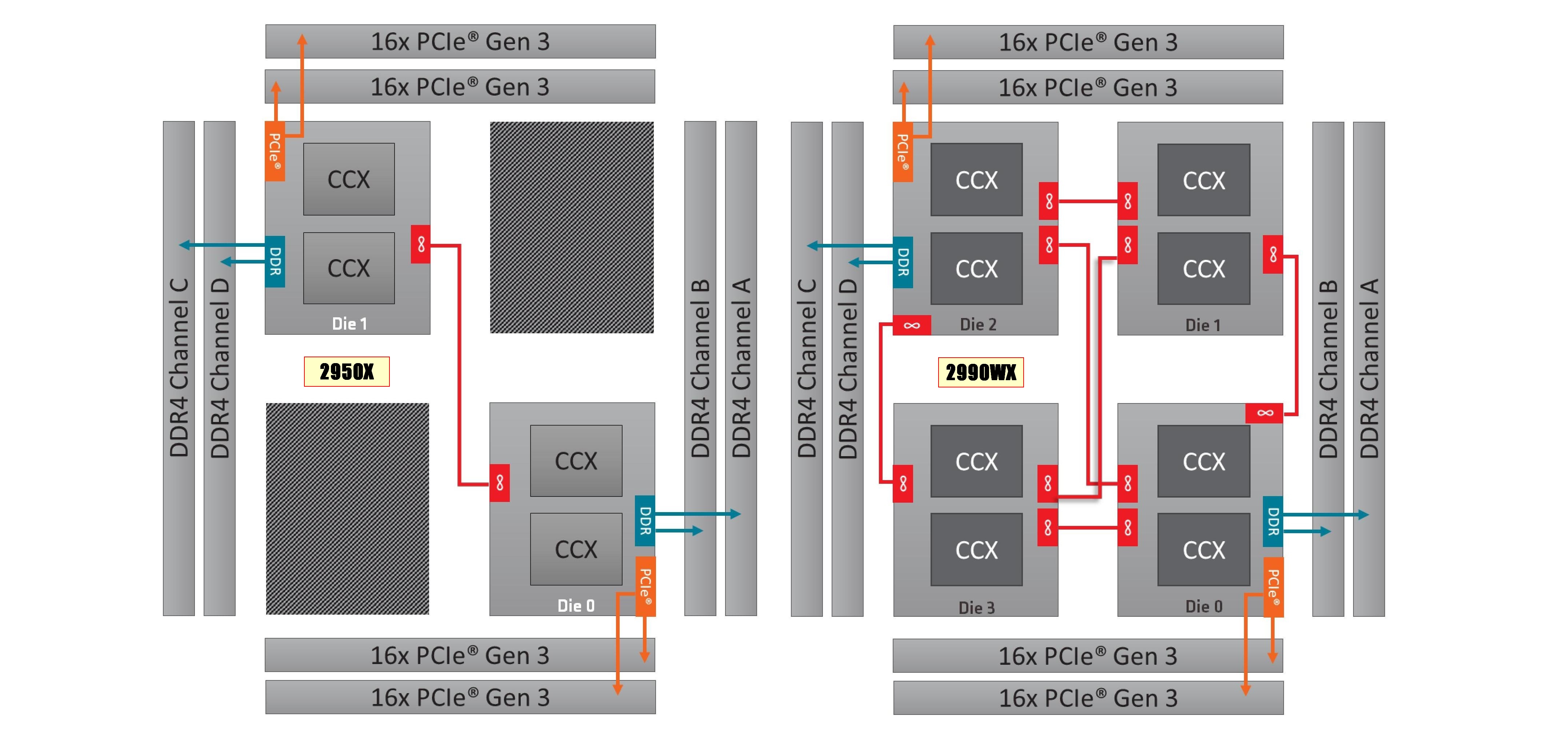
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
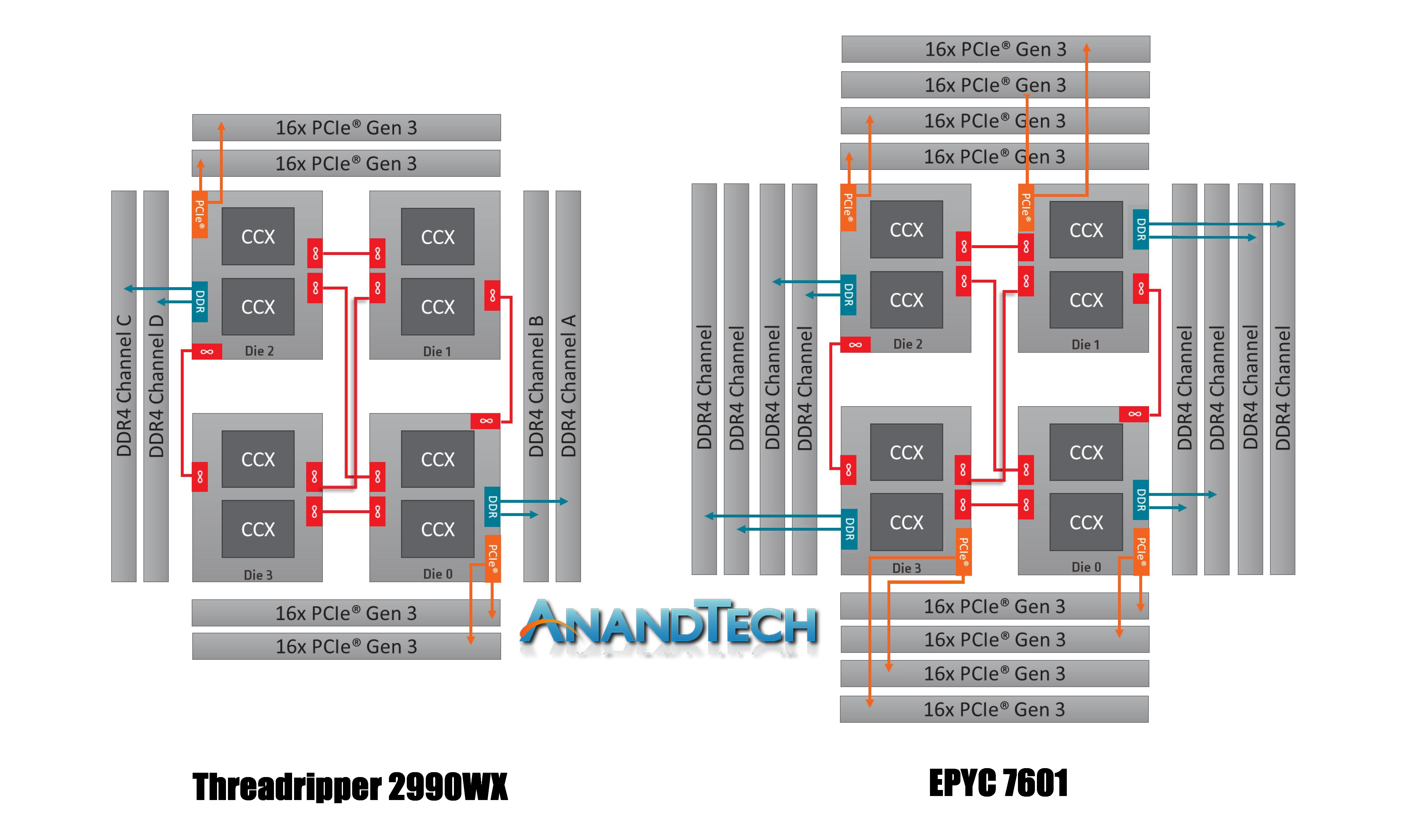
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
plonk420 - Tuesday, August 14, 2018 - link
worse for efficiency?https://techreport.com/r.x/2018_08_13_AMD_s_Ryzen_...
Railgun - Monday, August 13, 2018 - link
How can you tell? The article isn’t even finished.mapesdhs - Monday, August 13, 2018 - link
People will argue a lot here about performance per watt and suchlike, but in the real world the cost of the software and the annual license renewal is often far more than the base hw cost, resulting in a long term TCO that dwarfs any differences in some CPU cost. I'm referring here to the kind of user that would find the 32c option relevant.Also missing from the article is the notion of being able to run multiple medium scale tasks on the same system, eg. 3 or 4 tasks each of which is using 8 to 10 cores. This is quite common practice. An article can only test so much though, at this level of hw the number of different parameters to consider can be very large.
Most people on tech forums of this kind will default to tasks like 3D rendering and video conversion when thinking about compute loads that can use a lot of cores, but those are very different to QCD, FEA and dozens of other tasks in research and data crunching. Some will match the arch AMD is using, others won't; some could be tweaked to run better, others will be fine with 6 to 10 cores and just run 4 instances testing different things. It varies.
Talking to an admin at COSMOS years ago, I was told that even coders with seemingly unlimited cores to play with found it quite hard to scale relevant code beyond about 512 cores, so instead for the sort of work they were doing, the centre would run multilple simulations at the same time, which on the hw platform in question worked very nicely indeed (1856 cores of the SandyBridge-EP era, 14.5TB of globally shared memory, used primarily for research in cosmology, astrophysics and particle physics; squish it all into a laptop and I'm sure Sheldon would be happy. :D) That was back in 2012, but the same concepts apply today.
For TR2, the tricky part is getting the OS to play nice, along with the BIOS, and optimised sw. It'll be interesting to see how 2990WX performance evolves over time as BIOS updates come out and AMD gets feedback on how best to exploit the design, new optimisations from sw vendors (activate TR2 mode!) and so on.
SGI dealt with a lot of these same issues when evolving its Origin design 20 years ago. For some tasks it absolutely obliterated the competition (eg. weather modelling and QCD), while for others in an unoptimised state it was terrible (animation rendering, not something that needs shared memory, but ILM wrote custom sw to reuse bits of a frame already calculated for future frame, the data able to fly between CPUs very fast, increasing throughput by 80% and making the 32-CPU systems very competitive, but in the long run it was easier to brute force on x86 and save the coder salary costs).
There are so many different tasks in the professional space, the variety is vast. It's too easy to think cores are all that matter, but sometimes having oodles of RAM is more important, or massive I/O (defense imaging, medical and GIS are good examples).
I'm just delighted to see this kind of tech finally filter down to the prosumer/consumer, but alas much of the nuance will be lost, and sadly some will undoubtedly buy based on the marketing, as opposed to the golden rule of any tech at this level: ignore the publish benchmarks, the ony test that actually matters is your specific intended task and data, so try and test it with that before making a purchasing decision.
Ian.
AbRASiON - Monday, August 13, 2018 - link
Really? I can't tell if posts like these are facetious or kidding or what?I want AMD to compete so badly long term for all of us, but Intel have such immense resources, such huge infrastructure, they have ties to so many big business for high end server solutions. They have the bottom end of the low power market sealed up.
Even if their 10nm is delayed another 3 years, AMD will only just begin to start to really make a genuine long term dent in Intel.
I'd love to see us at a 50/50 situation here, heck I'd be happy with a 25/75 situation. As it stands, Intel isn't finished, not even close.
imaheadcase - Monday, August 13, 2018 - link
Are you looking at same benchmarks as everyone else? I mean AMD ass was handed to it in Encoding tests and even went neck to neck against some 6c intel products. If AMD got one of these out every 6 months with better improvements sure, but they never do.imaheadcase - Monday, August 13, 2018 - link
Especially when you consider they are using double the core count to get the numbers they do have, its not very efficient way to get better performance.crotach - Tuesday, August 14, 2018 - link
It's happened before. AMD trashes Intel. Intel takes it on the chin. AMD leads for 1-2 years and celebrates. Then Intel releases a new platform and AMD plays catch-up for 10 years and tries hard not to go bankrupt.I dearly hope they've learned a lesson the last time, but I have my doubts. I will support them and my next machine will be AMD, which makes perfect sense, but I won't be investing heavily in the platform, so no X399 for me.
boozed - Tuesday, August 14, 2018 - link
We're talking about CPUs that cost more than most complete PCs. Willy-waving aside, they are irrelevant to the market.Ian Cutress - Monday, August 13, 2018 - link
Hey everyone, sorry for leaving a few pages blank right now. Jet lag hit me hard over the weekend from Flash Memory Summit. Will be filling in the blanks and the analysis throughout today.But here's what there is to look forward to:
- Our new test suite
- Analysis of Overclocking Results at 4G
- Direct Comparison to EPYC
- Me being an idiot and leaving the plastic cover on my cooler, but it completed a set of benchmarks. I pick through the data to see if it was as bad as I expected
The benchmark data should now be in Bench, under the CPU 2019 section, as our new suite will go into next year as well.
Thoughts and commentary welcome!
Tamz_msc - Monday, August 13, 2018 - link
Are the numbers for test LuxMark C++ test correct? Seems they've been swapped(2900WX and 2950X).