AMD Unveils CDNA GPU Architecture: A Dedicated GPU Architecture for Data Centers
by Ryan Smith on March 5, 2020 5:25 PM EST- Posted in
- GPUs
- AMD
- Machine Learning
- Supercomputing
- AMD FAD 2020
- CDNA

Over the last decade, the industry has seen a boom in demand for GPUs for the data center. Driven in large part by rapid progress in neural networking, deep learning, and all things AI, GPUs have become a critical part of some data center workloads, and their role continues to grow with every year.
Unfortunately for AMD, they’ve largely been bypassed in that boom. The big winner by far as been NVIDIA, who has gone on to make billions of dollars in the field. Which is not to say that AMD hasn’t had some wins with their previous and current generation products, including the Radeon Instinct series, but their share of that market and its revenue has been a fraction of what NVIDIA has enjoyed.
AMD’s fortunes are set to change very soon, however. We already know that AMD (as a supplier to Cray) has scored two big supercomputer wins with the United States – totaling over $1 billion for CPUs and GPUs – so there have been a lot of questions on just what AMD has been working on that has turned the heads of the US government. The answer, as AMD is revealing today, is their new dedicated GPU architecture for data center compute: CDNA.
The Compute counterpart to the gaming-focused RDNA, CDNA is AMD’s compute-focused architecture for data center and other uses. Like everything else being presented at today’s Financial Analyst Day, AMD’s reveal here is at a very high level. But even at that high level, AMD is making it clear that there’s a fission of sorts going on in their GPU development process, leading to CDNA and RDNA becoming their own architectures.
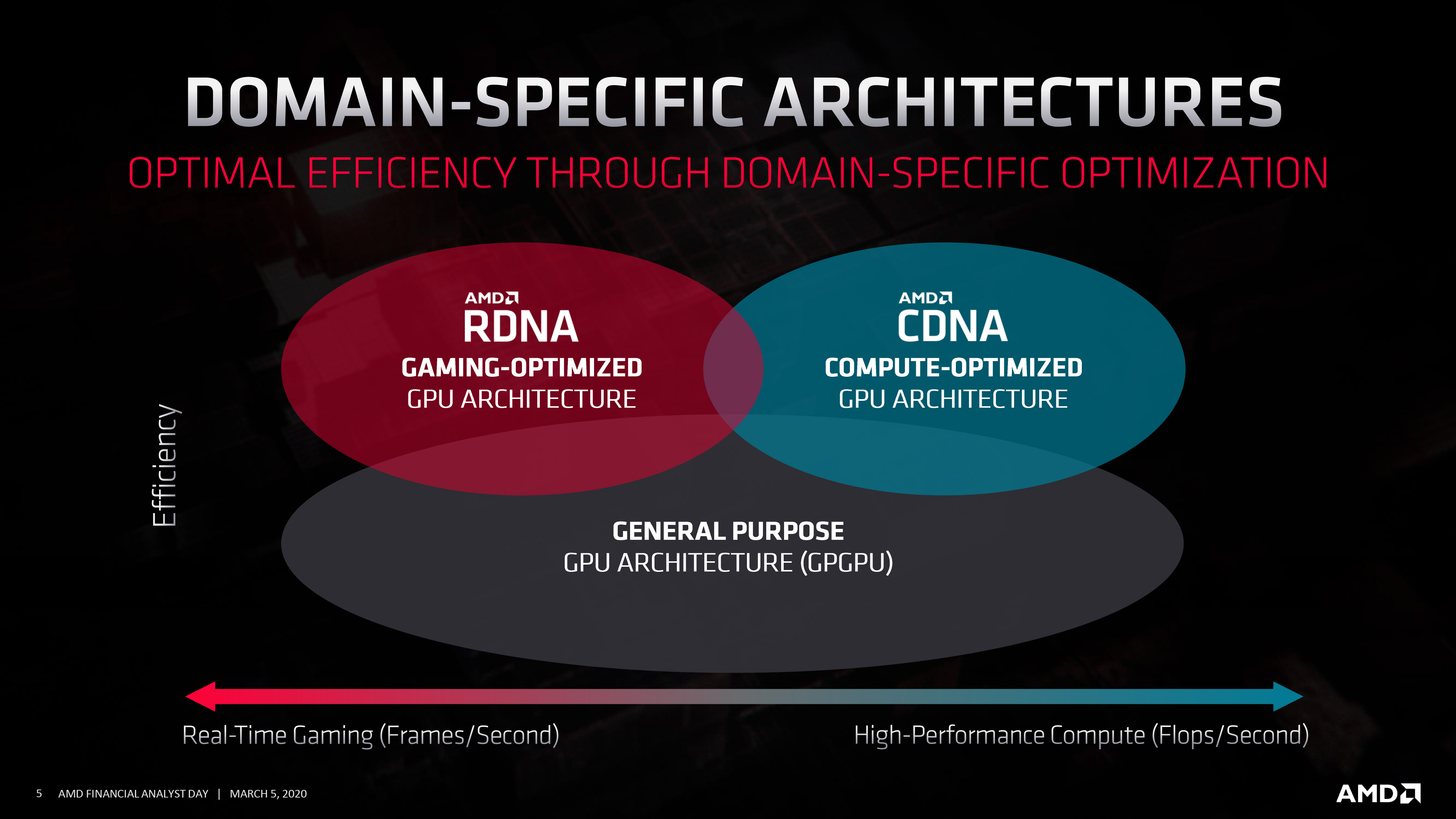
Just how different these architectures are (and over time, will be) remains to be seen. AMD has briefly mentioned that CDNA is going to have less “graphics-bits”, so it’s likely that these parts will have limited (if any) graphics capabilities, making them quite dissimilar from RDNA GPUs in some ways. So broadly speaking, AMD is now on a path similar to what we’ve seen from other GPU vendors, where compute GPUs are increasingly becoming a distinct class of product, as opposed to repurposed gaming GPUs.
AMD’s goals for CDNA are simple and straightforward: build a family of big, powerful GPUs that are specifically optimized for compute and data center usage in general. This is a path AMD already started to go down with GPUs such as Vega 20 (used in the Radeon Instinct MI 50/60), but now with even more specialization and optimization. A big part of this will of course be machine learning performance, which means supporting faster execution of smaller data types (e.g. INT4/INT8/FP16), and AMD even goes as far as to explicitly mention tensor ops. But this can’t come at the cost of traditional FP32/FP64 compute either; those supercomputers that AMD’s GPUs will be going in will be doing a whole lot of high precision math. So AMD needs to perform well across the compute and machine learning spectrum, across many data types.
To get there, AMD will also need to improve their performance-per-watt, as this is an area they have frequently trailed at. Today’s Financial Analyst Day announcement isn’t going into any real detail on how AMD is going to do this – beyond the obvious improvements in manufacturing processes, at least – but AMD is keenly aware of their need to improve.
All the while CDNA will also differentiate itself with features, including some things only AMD can do. Enterprise-grade reliability and security will be one leg here, including support for ever-popular virtualization needs.

But AMD will also be leaning on their Infinity Fabric to give them an edge in performance scaling and CPU/GPU integration. Infinity Fabric has been a big part of AMD’s success story this far on the CPU side of matters, and AMD is applying this same logic to the GPU side of matters. This means using IF to not only link GPUs to other GPUs, but using IF to link GPUs to CPUs. Which is something we’ve already seen in the works for AMD’s supercomputer wins, where both systems will be using IF to team up 4 GPUs with a single CPU.
AMD’s big win, however, will be a bit further down the line, when their 3rd gen Infinity Fabric is ready. It’s at that point where AMD intends to deliver a fully unified CPU/GPU memory space, fully leveraging their ability to provide both the CPUs and GPUs for a system. Unified memory can take a few different forms, so there are some important details that are missing here that will be saved for another day, but ultimately having a unified memory space should make programming heterogenous systems a whole lot easier, which in turn makes incorporating GPUs into servers all the better choice.
And since CDNA is now its own branch of AMD’s GPU architecture – with command of it falling under data center boss Forrest Norrod, interestingly enough – it also has its own roadmap with multiple generations of GPUs. With AMD treating Vega 20 as the branching point here, the company is revealing two generations of CDNA to come, aptly named CDNA (1) and CDNA 2.

CDNA (1) is AMD’s impending data center GPU. We believe this to be AMD’s “Arcturus”, and according to AMD it will be optimized for machine learning and HPC uses. This will be an Infinity Fabric-enabled part, using AMD’s second-generation IF technology. Keeping in mind that this is a high level overview, at this point it’s not super clear whether this part is going in either of AMD’s supercomputer wins; but given what we know so far about the later El Capitan – which is now definitely using CDNA 2 – CDNA (1) may be what’s ending up in Frontier.
Following CDNA (1) of course is CDNA 2. AMD is not sharing too much in the way of details here – after all, they haven’t yet shipped the first CDNA let alone the second – but they have confirmed that it will incorporate AMD’s third generation Infinity Fabric. As well, it will use a newer manufacturing node, which AMD is calling "Advanced Node" for now, as they are not disclosing the specific node they intend to use. So in a few different respects, CDNA 2 will be the piece de resistance of AMD’s heterogeneous compute plans, where they finally get to have a unified, coherent memory system across discrete CPUs and GPUs.
As for shipping dates, while AMD isn’t disclosing exact dates at this time, the roadmap itself only extends to the end of 2022, meaning that AMD expects to be shipping CDNA 2 in volume by then. This aligns fairly well with this week’s El Capitan announcement, which has the supercomputer being delivered in 2023.
Overall, AMD has some significant ambitions for their future data center GPUs. And while they have a lot of catching up to do to realize those ambitions, they’ve certainly laid out a promising roadmap to get there. AMD isn’t wrong about the importance of the data center market from both a technology perspective and a revenue perspective, and having a dedicated branch of their GPU architecture to get there may be just what AMD needs to finally find the success they seek.








25 Comments
View All Comments
WaltC - Friday, March 6, 2020 - link
It's pretty obvious that for awhile now AMD has enjoyed the "success they seek"...;) What they are doing now is seeking yet more success--just a slight correction. I'm wondering who it is with whom "they have a lot of catching up to do"--for Frontier and El Capitan they beat out Intel, IBM + nVidia--they don't award these things capriciously. AMD alone can do the CDNA architecture, for obvious reasons. AMD, unlike Intel, meets its execution targets--that is inarguable.mode_13h - Sunday, March 8, 2020 - link
> It's pretty obvious that for awhile now AMD has enjoyed the "success they seek"...;)You're just looking at their overall business success. You can't be talking about AI penetration, because they've utterly failed on that front. Their HPC penetration has also been quite weak, though not quite as dismal.
> for Frontier and El Capitan they beat out Intel, IBM + nVidia--they don't award these things capriciously
I'm not sure about that. DoE seems to be rotating through vendors, giving everyone a bite. Maybe they're trying to avoid putting all their eggs in one basket, out of security concerns. Maybe, they just want to help sustain more than one domestic supplier. I wouldn't assume they do it 100% on price/performance, though.
> AMD, unlike Intel, meets its execution targets--that is inarguable.
Intel's problem is manufacturing, not design. Intel meets its design targets (or, at least we have no evidence they don't). AMD doesn't do manufacturing. Solution: Intel should just use TSMC/Samsung and they can start winning again, too.
Intel still won a big US Government HPC contract (I forget which), even in spite of their current delivery track record.
JayNor - Monday, June 8, 2020 - link
Intel's design for Aurora includes pcie5/cxl that would get them to full cpu and gpu cache coherency a generation before AMD's cdna2 solution. In addition, the asymmetric coherency solution of cxl seems to be acknowledged as a benefit. Perhaps AMD will adopt it in cdna2.Yes, Intel had delays due to 10nm fab issues, but it looks like the design people stayed busy.
ksec - Friday, March 6, 2020 - link
Literally just said this yesterday in the El Capitan comment section. Kind of nice to see this being true.ballsystemlord - Saturday, March 7, 2020 - link
Thanks, ryan!