Russia’s Elbrus 8CB Microarchitecture: 8-core VLIW on TSMC 28nm
by Dr. Ian Cutress on June 1, 2020 8:00 AM EST
All of the world’s major superpowers have a vested interest in building their own custom silicon processors. The vital ingredient to this allows the superpower to wean itself off of US-based processors, guarantee there are no supplemental backdoors, and if needed add their own. As we have seen with China, custom chip designs, x86-based joint ventures, or Arm derivatives seem to be the order of the day. So in comes Russia, with its custom Elbrus VLIW design that seems to have its roots in SPARC.
Russia has been creating processors called Elbrus for a number of years now. For those of us outside Russia, it has mostly been a big question mark as to what is actually under the hood – these chips are built for custom servers and office PCs, often at the direction of the Russian government and its requirements. We have had glimpses of the design, thanks to documents from Russian supercomputing events, however these are a few years old now. If you are not in Russia, you are unlikely to ever get your hands on one at any rate. However, it recently came to our attention of a new programming guide listed online for the latest Elbrus-8CB processor designs.

The latest Elbrus-8CB chip, as detailed in the new online programming guide published this week, built on TSMC’s 28nm, is a 333 mm2 design featuring 8 cores at 1.5 GHz. Peak throughput according to the documents states 576 GFLOPs of single precision, with the chip offering four channels of DDR4-2400, good for 68.3 GB/s. The L1 and L2 caches are private, with a 64 kB L1-D cache, a 128 kB L1-I cache, and a 512 kB L2 cache. The L3 cache is shared between the cores, at 2 MB/core for a total of 16 MB. The processor also supports 4-way server multiprocessor combinations, although it does not say on what protocol or what bandwidth.
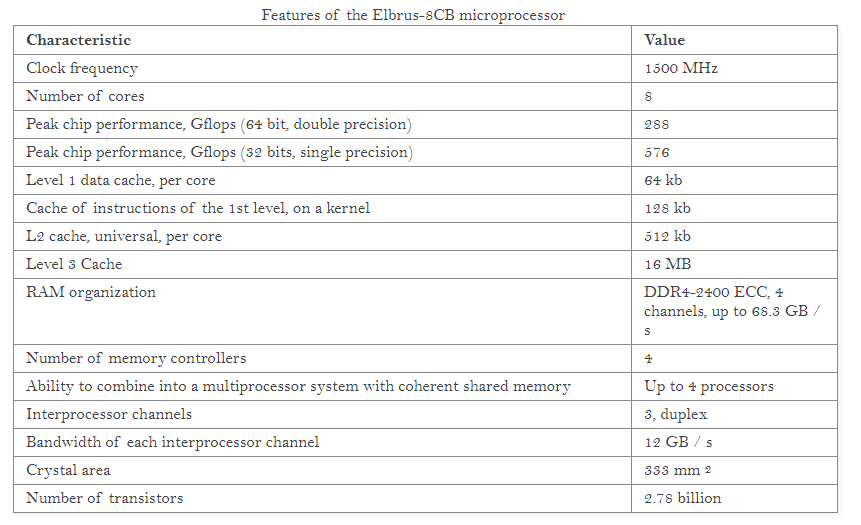
It is a compiler focused design, much like some other complex chips, in that most of the optimizations happen at the compiler level. Based on compiler first designs in the past, that typically does not make for a successful product. Documents from 2015 state that a continuing goal of the Elbrus design is x86 and x86-64 binary translation with only a 20% overhead, allowing full support for x86 code as well as x86 operating systems, including Windows 7 (this may have been updated since 2015).
The core has six execution ports, with many ports being multi-capable. For example, four of the ports can be load ports, and two of the ports can be store ports, but all of them can do integer operations and most can do floating point operations. Four of the ports can do comparison operations, and those four ports can also do vector compute.
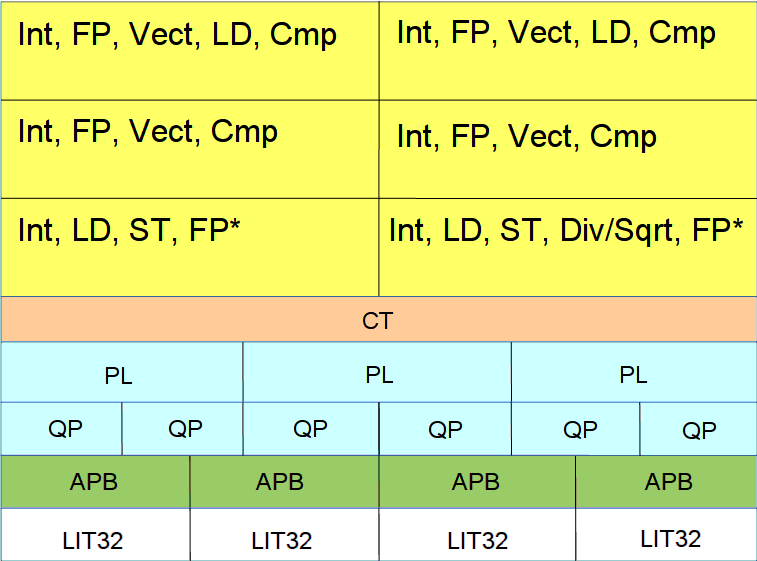
Elbrus 8CB Core
This short news post is not meant to be a complete breakdown of the Elbrus capabilities – we have amusingly joked internally at what frequency a Cortex X1 with x86 translation would match the capabilities of the 8-core Elbrus, however users who want to get to grips with the design can open and read the documentation at the following address:
http://ftp.altlinux.org/pub/people/mike/elbrus/docs/elbrus_prog/html/index.html
The bigger question is going to be how likely any of these state-funded processor development projects are going to succeed at scale. State-funded groups should, theoretically, be the best funded, however even with all the money in the world, engineers are still required to get things done. Even if there ends up being a new super-CPU for a given superpower, there will always be vested interests in an amount of security though obscurity, especially if the hardware is designed specifically to cater to state-secret levels of compute. There's also the added complication of the US government tightening its screws around TSMC and ASML to not accept orders from specific companies - any plans to expand those boundaries could occur, depending how good the products are or how threatened some nations involved feel.
Source: Blu (Twitter)








93 Comments
View All Comments
regsEx - Tuesday, June 2, 2020 - link
Argumentum ad verecundiam. Not really a cultural way of doing discussion.https://en.wikipedia.org/wiki/Argument_from_author...
mode_13h - Tuesday, June 2, 2020 - link
My point was quite simply that a number of people on here like to talk about IA64, but they clearly don't understand it well enough to be making the points they're reaching for.I'll admit that it's not exactly a polite thing to say, but sometimes the situation calls for a summation or a meta-level comment, rather than getting bogged down in a point-by-point refutation.
It's not a thing I say with any animus. If people want to educate themselves about it, I'd be happy to see that, and it would benefit us all by enabling a more enlightened and enlightening discussion.
As for my "appear to authority", I just wanted to make it clear that I didn't mean for my words to apply to that poster.
mode_13h - Monday, June 1, 2020 - link
Funny thing is that VLIW and SIMD are orthogonal. In fact, if you have a wide enough SIMD, you don't even need VLIW. Kind of like modern GPUs.mshigorin - Monday, June 1, 2020 - link
Those GPUs aren't exactly general purpose CPUs through that, erm? Try running e.g. bzflag purely on your NVIDIA GPU.Alexvrb - Monday, June 1, 2020 - link
Except you don't have to run GPUs by themselves. You're using general purpose CPUs plus accelerators geared towards your purpose, and balance them according to your needs. Using multiple designs (as needed) that excel at different tasks is better than a single design that is mediocre at everything.mshigorin - Tuesday, June 2, 2020 - link
> that is mediocre at everythingThis is not true (as generalizations that wide tend to be); my point was that one *can* actually use e2k *without* extra accelerators "as is" for quite a few task classes (which is what happened with x86 before either, recall hardware modems vs softmodems for example), *and* one can add accelerators as well. So far I'd only like a "js accelerator" for my Elbrus 801-PC as I've mentioned in this discussion already, and it's not that bad as it is (with quite some improvement potential on the existing architecture as the developers say).
Come to Moscow when covid19 starts getting old, visit Yandex Museum and witness folks playing games and watching videos in 4K on a 801-PC with RX580 (yes, a GPU), maybe that will help to improve generalization ;-)
mode_13h - Monday, June 1, 2020 - link
Right. I was just replying to @azfacea's apparent conflation of SIMD and VLIW, and citing modern GPUs as an example of "massive SIMD performance" that doesn't involve VLIW.mshigorin - Monday, June 1, 2020 - link
Both statements are actually wrong.1. the compilers have a better chance to realize that parallelism during compile-time than half-a-chip CISC decoder has in realtime; and sometimes the pipeline would need to be over 1000 instructions long for the hardware scheduler to be able to predict branches correctly (there's a known case where a 500 MHz e2k v2 would outperform a core2duo at 1.5 GHz or so, for example). You meant something way less more dogmatic, I am sure.
2. I've started e2kv4 works using my existing e2kv3 system -- they differ even in the maximum number of elementary operations per clock (23/25) but the code ran just fine, I've measured about 1% difference between p7zip build for v3/v4 and running on v4 (no optimization by hand though).
If Intel/HP failed at an impossible task, they just lacked those Russian hackers that one is required to have ready for a job. And I know some lcc guys ;-)
azfacea - Monday, June 1, 2020 - link
its funny how i am hearing the same things in 2020 that i was reading in kernel mailing lists in 2003, i guess the whole industry is not as smart as you are and hasnt been able to figure this out in 20 years. of course "You meant something way less more dogmatic, I am sure."mode_13h - Monday, June 1, 2020 - link
He posted data and you countered with rhetoric? If you're not feeling bad for yourself, I'll feel bad for you.The classic dilemma of VLIW:
"Runtime is when you know the most about how to schedule code, but it's also too late to do much about it."
I read that somewhere in the run up to Itanium's launch. Anyway, profile-driven recompilation isn't a bad way to split the difference.
Also, not sure where you got the idea about compilers being "impossible to write".
And Itanium failed because "the whole industry is not as smart as you"? Are you sure about that?