What Products Use Intel 10nm? SuperFin and 10++ Demystified
by Dr. Ian Cutress on September 25, 2020 9:00 AM EST_678x452.jpg)
For our audience that regularly keeps track of Intel’s product portfolio, it would be hard to miss that the naming strategy of Intel’s process node technologies is a bit of a mess. To some, those words are themselves an understatement, as Intel has shifted its naming strategy 2-3 times since the launch of Intel’s first 10nm products. Not only that, even Intel’s various departments internally have a hard time keeping track of ‘what is this manufacturing process being called today’ when the press like AnandTech ask for details on the latest upcoming products.
Knowing this, and knowing what issues Intel has been having, I wanted to demystify Intel’s manufacturing process naming scheme such that users and engineers alike, even if they are inside Intel, can understand what is what but also importantly why. The why is the crucial factor.
If you're looking for a handy decoder ring for Intel's 10nm Products, it's here in page 3.
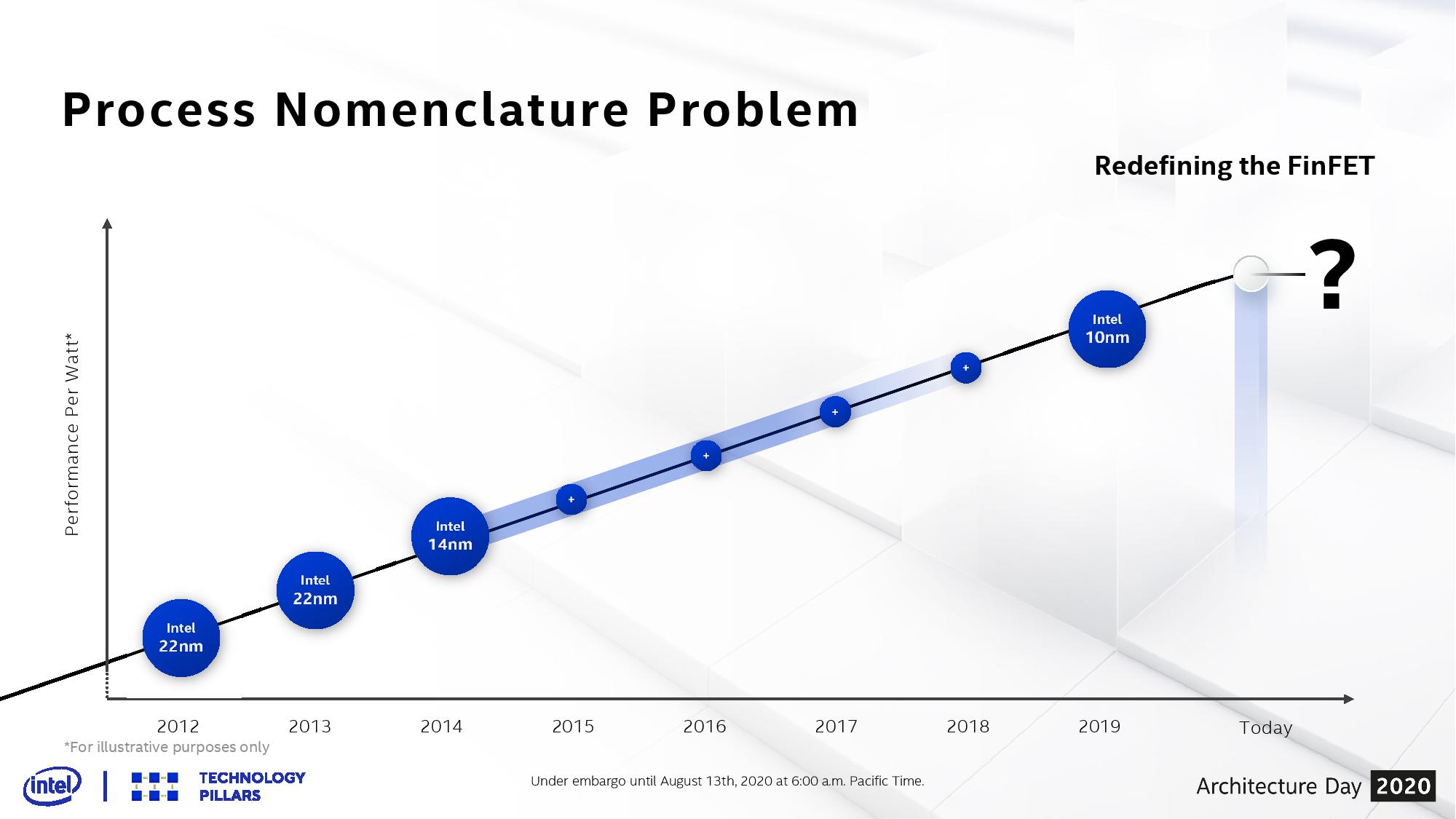
Why Do We Have Multiple Versions of a Process?
With Intel’s 14nm, we were invited to 14nm, 14+, 14++, 14+++, and if you believe Intel’s own slides, there were variants that went beyond this ++++ naming scheme. Each one of those additional + points on the end of the name signified a change in the process technology – usually to assist for increasing performance or efficiency.
Each one of these + points is an update to the BKM, or Best Known Methods.
While an engineer can draw an electrical layouts for a part of a processor, such as an addition circuit, actually applying that design to a silicon floorplan for manufacturing is a different skill altogether. Transistor libraries are designed to take advantage of a given process, and when a floorplan is optimized for a process, it can then be pasted and repeated as necessary – on top of this, simulation on thermals, power, and current density are applied to ensure that there are no hotspots or that critical paths inside the design have as few bottlenecks as possible.
When an update to the BKM occurs, two things can happen. Normally we see the update on the level of the transistor library that is changed – if the distance between two fins on a transistor increases for example, the transistor library and the macros may be made bigger, and then the floorplan might be redesigned to take account for this. As for any process node design, there are 100 different controls, and improving one might make three other controls worse, so it is a fine balancing act. Not only this, but the BKM has to be validated at the manufacturing level. The BKM update could apply to the metal stack as well, which in of itself can adjust the performance.

Lots of dials at each stage
In the long long past, BKM updates were never advertised externally. If Intel or TSMC or another foundry discovered a way to improve the performance, or decrease the voltage, or improve the yield, the update was silently rolled into the design and nothing much was made of it. Sometimes processors would be listed as ‘1.0 volts to 1.35 volts’, and it would just be a roll of the dice if a user obtained one of the lower voltage models.
However, as time between different process node updates has elongated, these BKM updates have started to be identified and effectively monetized by the semiconductor companies. An update to a process that improves the voltage by 50 millivolts and increases frequency by 200 MHz immediately becomes a productizable event, and products built on these updates can be offered for more money over the usual. Or, depending on the rate of updates, the whole next generation of products could be built on the update.

So we never saw BKM updates officially announced at Intel’s 45nm, 32nm, or 22nm process nodes. These updates were fast enough that the productization of any update didn’t warrant a full round of marketing. With 14nm, that changed.
Intel had discussed its roadmap beyond 14nm since its 2010 Investor Meeting. It predicted that the company would be on 14nm by 2013, 10nm by 2015, and 7nm by 2017. As we now know, 14nm was two years late, and 10nm was 2-4 years late. Because of the introduction of 10nm being delayed, Intel decided to productize its 14nm BKM updates, and signified those with + points.
Intel’s current official line is that there have been four updates to 14nm, creating five ‘generations’.
More Plus Means More Meme
Because of all the + points, Intel’s marketing sometimes getting it wrong, and perhaps a little bit of ‘++’ in most programming languages meaning ‘+1’, the whole concept of adding + to the process node has become a meme – a meme at Intel’s expense, purely on the basis of its failure to deliver 10nm before the 14++++ naming scheme got out of hand.









143 Comments
View All Comments
lilo777 - Friday, September 25, 2020 - link
I totally agree. People obsessed with process names should check this article - https://hexus.net/tech/news/cpu/145645-intel-14nm-...It shows that transistor density of Intel 14nm+++ is close to that of AMD/TSMC 7nm.
Spunjji - Friday, September 25, 2020 - link
It really isn't when you compare the whole chip - they appear to have compared some of the worst structures for scaling in that article.Nobody's really obsessed with names - they just serve a useful purpose for discussing differences.
lilo777 - Friday, September 25, 2020 - link
They are not. After advent of finfet (and maybe even before it) process names do not carry any useful information about the merits of the process. It's just a name of the menu item in foundry's catalog. If they wanted to, Intel could name their next process 1nm. They won't. Nobody cares.Spunjji - Monday, September 28, 2020 - link
Process names stopped relating to most structure sizes way before FinFet, and I'm well aware that the name itself - on its own - doesn't convey useful information about the process. What they do convey is which process came after which for a given foundry, they imply significant difference such as a decrease in average feature size, and sometimes they convey a general idea of which industry generation the process belongs to. what they don't tell you is whose foundry produces smaller and/or more performant transistors, but as I said in the first place, they're useful as a simple reference point for discussion; you can't easily discuss something that doesn't have a name.Intel won't name their next generation 1nm because it wouldn't be the next logical step after their current generation. You're literally proving yourself wrong by pointing out that they won't do that.
You also totally skipped past copping to the falsehood that 14nm+++ is "close to" TSMC 7nm. 14nm++ is around 37.22 MTr/mm² (Source: https://en.wikichip.org/wiki/mtr-mm%C2%B2 ) while Renoir on 7nm measures in at about 63 MTr/mm².
FullmetalTitan - Saturday, September 26, 2020 - link
That TEM cut looks an awful lot like SRAM block, which has notoriously poor scaling with design node. SRAM cells from 28nm generations are not double the size of 14nm SRAM cells, more like 20% larger.However as you point out in your next comment, node naming stopped being a useful metric, somewhere between 65nm and 45nm. The industry stuck with it based on IEEE roadmap of full-node step naming, but it doesn't remotely align with the reality. The old standard was full width half pitch, since the center to center distance between gates was approximately aligned with the channel width. Intel led the industry departure from that standard, instead measuring the effective gate length. In later generations of planar nodes (45nm and smaller) gates were packed densely enough that FWHP was not accurately representing gate width anymore, it was SMALLER than the gate dimension. With FINFETs that actually went a bit far in the other direction since the control surface width of a fin is not the same as a planar device, since the gate wraps over the fin and the surface area is the important factor in design and operation. For the 14/16nm generation of devices, the minimum feature size of interest was actually 6-7nm for Intel, TSMC, and Samsung nodes.
Spunjji - Monday, September 28, 2020 - link
Yup, you nailed it on that one. False conclusion (similar density) drawn from incomplete information (only one type of transistor measured).RSAUser - Saturday, September 26, 2020 - link
These are all from "IC Knowledge LCC" as posted by electronics weekly.Transistor density (MTx/mm2)
Intel 10nm: 106
Samsung 5LPE: 133.56
TSMC 5FF: 185.46
Then from other places, this is Wikipedia, but following links to check that they're right:
TSMC N7FF (First generation 7nm): 96.5
So TSMC's first 7nm generation is nearly as dense as Intel's first 10nm, interesting. Meanwhile TSMC's N7FF+ is 114, Apple's A13 chip is built on this.
Their 5nm node is supposedly 186, it's used for Apple's A14 chip.
Spunjji - Monday, September 28, 2020 - link
That number for Intel 10nm isn't accurate - it was their original target and it hasn't been reached in practice. It looks like they had to relax a lot of their design rules to make the process yield well.Anandtech's quoted number for density with Lakefield is 49.4 MTr/mm², while apparently Tiger Lake is closer to 40 MTr/mm².
Bagheera - Tuesday, March 9, 2021 - link
you should check this article:https://semiwiki.com/semiconductor-services/ic-kno...
it's by someone who actually know we what they are taking about.
Ian Cutress - Friday, September 25, 2020 - link
Billions of dollars go into process steps. Talking about next gen processors isn't all about performance - it's the industry of the hardware that goes into building machines to enable those processes. Hundreds of thousands of jobs, supply chains, the works. So yes, we do care about process node technology. A whole friggin lot.I once heard from an Intel exec that told a bunch of press who started asking about 10nm that 'process node doesn't matter'. I came down on him like a ton of bricks. I haven't seen him speak to the press since. I hope it's not you.