The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
Compiling Performance / LLVM
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk – on a 4KB page system 5GB should be sufficient but on the Altra’s 64KB system it used up to 9.5GB, including the source directory. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
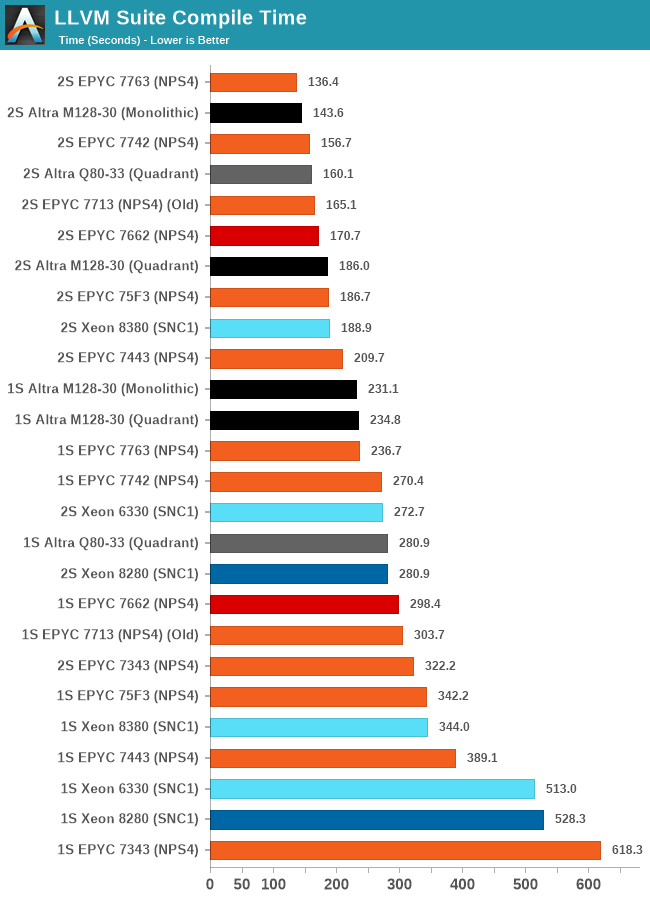
The LLVM compile test results here are quite more special and demand more attention that what meets the eye at first.
Inherently, the biggest work slice of the test is massively parallel, able to take advantage of all cores in a system, 256 cores in the 2-socket results of the M128-30, however as it’s also a real-world test, the compilation also incurs linking phases where the chip is inherently just under a single-core load and all other cores are just sitting idle.
This behaviour results in some more complex behaviour in the different test scenarios of the M128-30, as the ratio between the parallel/MT and ST phases of the test changes.
In the single-socket results, the chip showcases a +14% performance boost over the Q80-33, while in the 2S results under quadrant mode, this actually transforms into a 16% performance regression. What’s happening here is that while the increased core count of the chip massively helps in improving the actual compilation of objects, the linking phase of the test is significantly slower and takes up a larger percentage of total test time than on the Q80-33, due to the lower CPU frequencies and smaller SLC of the new chip.
Running the M128-30 in monolithic mode actually results in a 24% reduction in compile time, mostly through a large speedup of the linking phase of the compilation as we’re giving that one active core access to the whole 16MB SLC rather than just a 4MB slice.
AMD’s EPYC 7763, even though it has only half the core count, still manages to outperform the M128-30 in the total test time because the linking phase is much sped up thanks to the much superior single-threaded performance of the cores when few threads are active on the SoC. The 34% advantage of the ST SPEC scores here comes more into play than the MT throughput of the chip.
These results are very interesting, and showcase that even in a more real-world scenario like this, the flock-of-chickens approach doesn’t work out as well even in what would consider a massively parallel workload, as some things just cannot be spread out over multiple cores well. It reminds me very much of the eMAG chip, which also suffered in real world code compilations due to the very same reasons.








60 Comments
View All Comments
lemurbutton - Thursday, October 7, 2021 - link
Before AMD can disrupt Intel in the server, Ampere has disrupted AMD. And now Intel is coming back with Saphire Rapids. Doesn't look good for AMD.Teckk - Thursday, October 7, 2021 - link
AMD also has upcoming products, same as other companies :) Competition is good.schujj07 - Thursday, October 7, 2021 - link
Most likely Sapphire Rapids will only get Intel to Epyc Milan or a little past there. Overall ICL Xeon only caught Intel up to Epyc Rome. Initial tests on Milan were good, showing 5-7% better performance which isn't bad, however, it wasn't like what we saw on the desktop side. Turns out the benchmarks were run on a reference platform that AMD hacked to allow 3rd Gen support. Once benchmarks were done on Milan on platforms designed for 3rd Gen the performance jumped by another 10% or more. Basically that put ICL 15-17% behind Epyc Milan and SPR is only supposed to get about 19% more performance.mode_13h - Thursday, October 7, 2021 - link
> Initial tests on Milan were good, showing 5-7% better performance which isn't badInitial tests were flawed, due to non-production hardware/firmware. Check out their update:
https://www.anandtech.com/show/16778/amd-epyc-mila...
schujj07 - Thursday, October 7, 2021 - link
"Initial tests were flawed, due to non-production hardware/firmware."I basically said that in my initial comment.
"Turns out the benchmarks were run on a reference platform that AMD hacked to allow 3rd Gen support. Once benchmarks were done on Milan on platforms designed for 3rd Gen the performance jumped by another 10% or more. "
GreenReaper - Saturday, October 9, 2021 - link
Your initial comment was too long, he didn't read that far before hitting reply.whatthe123 - Thursday, October 7, 2021 - link
icelake is not great in general. it was an improvement over 14nm but the core scaling was not there and their 10nm was still struggling to hit competitive boost clocks. I don't think the uplift they saw between 14nm and icelake reflects sapphire rapids at all considering the major design changes and improved node, but if it does I don't see how sapphire rapids would compete with milan at a lower core count. If its competing with milan then the per-core performance and MT scaling has seen a huge uplift compared to icelake.schujj07 - Thursday, October 7, 2021 - link
Had ICL come out on time people would have been more impressed. The problem that ICL has is since it was soooooo late Intel had to squeeze every ounce of performance out of SKL. Overall ICL is just a short term platform but the performance comparison to SPR.mode_13h - Friday, October 8, 2021 - link
> Had ICL come out on time people would have been more impressed.Depends on what you mean by "on time". If it had come in place of Cascade Lake, then probably. However, if it still followed Cascade Lake, then the clockspeed drop and strong competition from Rome & comparison with Graviton 2 are still unflattering.
If Ice Lake had notched up the clockspeed ladder *and* launched in place of Cascade Lake, then it would've been a very solid entry.
Anyway, I'm sure Intel is still selling every one they can make. People are quick to point out how AMD benefited from Intel's process woes, but the past 5 years' demand surge has provided Intel a very nice cushion. They basically couldn't have picked a better time to falter.
schujj07 - Friday, October 8, 2021 - link
I believe that ICL was supposed to be 2nd Gen Scalable. When Intel found that it wasn't ready, they released Cascade Lake. Even worse was needing to release Cooper Lake for 4-8S systems in 2H 2020.