The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTFundamental Windows 10 Issues: Priority and Focus
In a normal scenario the expected running of software on a computer is that all cores are equal, such that any thread can go anywhere and expect the same performance. As we’ve already discussed, the new Alder Lake design of performance cores and efficiency cores means that not everything is equal, and the system has to know where to put what workload for maximum effect.
To this end, Intel created Thread Director, which acts as the ultimate information depot for what is happening on the CPU. It knows what threads are where, what each of the cores can do, how compute heavy or memory heavy each thread is, and where all the thermal hot spots and voltages mix in. With that information, it sends data to the operating system about how the threads are operating, with suggestions of actions to perform, or which threads can be promoted/demoted in the event of something new coming in. The operating system scheduler is then the ring master, combining the Thread Director information with the information it has about the user – what software is in the foreground, what threads are tagged as low priority, and then it’s the operating system that actually orchestrates the whole process.
Intel has said that Windows 11 does all of this. The only thing Windows 10 doesn’t have is insight into the efficiency of the cores on the CPU. It assumes the efficiency is equal, but the performance differs – so instead of ‘performance vs efficiency’ cores, Windows 10 sees it more as ‘high performance vs low performance’. Intel says the net result of this will be seen only in run-to-run variation: there’s more of a chance of a thread spending some time on the low performance cores before being moved to high performance, and so anyone benchmarking multiple runs will see more variation on Windows 10 than Windows 11. But ultimately, the peak performance should be identical.
However, there are a couple of flaws.
At Intel’s Innovation event last week, we learned that the operating system will de-emphasise any workload that is not in user focus. For an office workload, or a mobile workload, this makes sense – if you’re in Excel, for example, you want Excel to be on the performance cores and those 60 chrome tabs you have open are all considered background tasks for the efficiency cores. The same with email, Netflix, or video games – what you are using there and then matters most, and everything else doesn’t really need the CPU.
However, this breaks down when it comes to more professional workflows. Intel gave an example of a content creator, exporting a video, and while that was processing going to edit some images. This puts the video export on the efficiency cores, while the image editor gets the performance cores. In my experience, the limiting factor in that scenario is the video export, not the image editor – what should take a unit of time on the P-cores now suddenly takes 2-3x on the E-cores while I’m doing something else. This extends to anyone who multi-tasks during a heavy workload, such as programmers waiting for the latest compile. Under this philosophy, the user would have to keep the important window in focus at all times. Beyond this, any software that spawns heavy compute threads in the background, without the potential for focus, would also be placed on the E-cores.
Personally, I think this is a crazy way to do things, especially on a desktop. Intel tells me there are three ways to stop this behaviour:
- Running dual monitors stops it
- Changing Windows Power Plan from Balanced to High Performance stops it
- There’s an option in the BIOS that, when enabled, means the Scroll Lock can be used to disable/park the E-cores, meaning nothing will be scheduled on them when the Scroll Lock is active.
(For those that are interested in Alder Lake confusing some DRM packages like Denuvo, #3 can also be used in that instance to play older games.)
For users that only have one window open at a time, or aren’t relying on any serious all-core time-critical workload, it won’t really affect them. But for anyone else, it’s a bit of a problem. But the problems don’t stop there, at least for Windows 10.
Knowing my luck by the time this review goes out it might be fixed, but:
Windows 10 also uses the threads in-OS priority as a guide for core scheduling. For any users that have played around with the task manager, there is an option to give a program a priority: Realtime, High, Above Normal, Normal, Below Normal, or Idle. The default is Normal. Behind the scenes this is actually a number from 0 to 31, where Normal is 8.
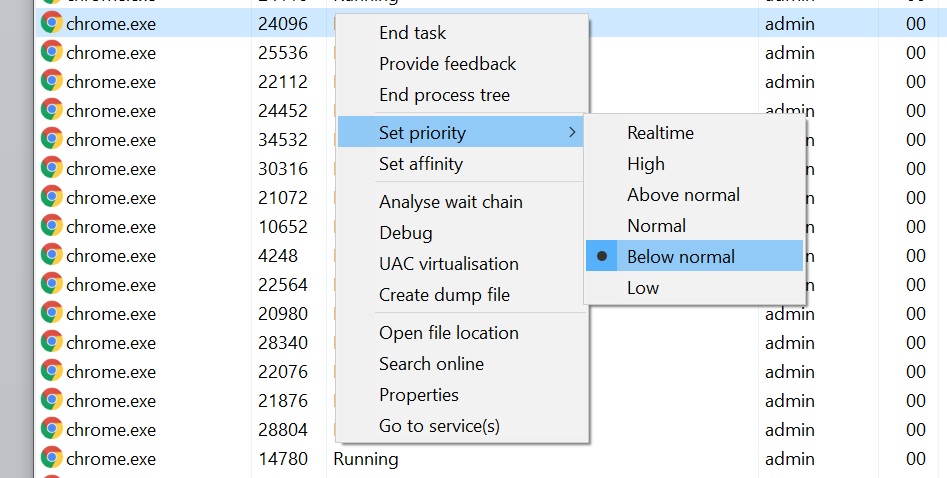
Some software will naturally give itself a lower priority, usually a 7 (below normal), as an indication to the operating system of either ‘I’m not important’ or ‘I’m a heavy workload and I want the user to still have a responsive system’. This second reason is an issue on Windows 10, as with Alder Lake it will schedule the workload on the E-cores. So even if it is a heavy workload, moving to the E-cores will slow it down, compared to simply being across all cores but at a lower priority. This is regardless of whether the program is in focus or not.
Of the normal benchmarks we run, this issue flared up mainly with the rendering tasks like CineBench, Corona, POV-Ray, but also happened with yCruncher and Keyshot (a visualization tool). In speaking to others, it appears that sometimes Chrome has a similar issue. The only way to fix these programs was to go into task manager and either (a) change the thread priority to Normal or higher, or (b) change the thread affinity to only P-cores. Software such as Project Lasso can be used to make sure that every time these programs are loaded, the priority is bumped up to normal.








474 Comments
View All Comments
Oxford Guy - Sunday, November 7, 2021 - link
‘or maybe switch off their E-cores and enable AVX-512 in BIOS’This from exactly the same person who posted, just a few hours ago, that it’s correct to note that that option can disappear and/or be rendered non-functional.
I am reminded of your contradictory posts about ECC where you mocked advocacy for it (‘advocacy’ being merely its mention) and proceeded to claim you ‘wish’ for more ECC support.
Once again, it’s helpful to have a grasp of what one actually believes prior to posting. Allocating less effort to posting puerile insults and more toward substance is advised.
mode_13h - Sunday, November 7, 2021 - link
> This from exactly the same person who posted, just a few hours ago, that it’s> correct to note that that option can disappear and/or be rendered non-functional.
You need to learn to distinguish between what Intel has actually stated vs. the facts as we wish them to be. In the previous post you reference, I affirmed your acknowledgement that the capability disappearing would be consistent with what Intel has actually said, to date.
In the post above, I was leaving open the possibility that *maybe* Intel is actually "cool" with there being a BIOS option to trade AVX-512 for E-cores. We simply don't know how Intel feels about that, because (to my knowledge) they haven't said.
When I clarify the facts as they stand, don't confuse that with my position on the facts as I wish them to be. I can simultaneously acknowledge one reality, which maintaining my own personal preference for a different reality.
This is exactly what happened with the ECC situation: I was clarifying Intel's practice, because your post indicated uncertainty about that fact. It was not meant to convey my personal preference, which I later added with a follow-on post.
Having to clarify this to an "Oxford Guy" seems a bit surprising, unless you meant like Oxford Mississippi.
> you mocked advocacy
It wasn't mocking. It was clarification. And your post seemed more to express befuddlement than expressive of advocacy. It's now clear that your post was a poorly-executed attempt at sarcasm.
Once again, it's helpful not to have your ego so wrapped up in your posts that you overreact when someone tries to offer a factual clarification.
Oxford Guy - Monday, November 8, 2021 - link
I now skip to the bottom of your posts If I see more of the same preening and posing, I spare myself the rest of the nonsense.mode_13h - Tuesday, November 9, 2021 - link
> If I see more of the same preening and posing, I spare myself the rest of the nonsense.Then I suggest you don't read your own posts.
I can see that you're highly resistant to reason and logic. Whenever I make a reasoned reply, you always hit back with some kind of vague meta-critique. If that's all you've got, it can be seen as nothing less than a concession.
O-o-o-O - Saturday, November 6, 2021 - link
Anyone talking about dumping x64 ISA?I don't see AVX-512 a good solution. Current x64 chips are putting so much complexity in CPU with irrational clock speed that migrating process-node further into Intel4 on would be a nightmare once again.
I believe most of the companies with in-house developers expect the end of Xeon-era is quite near, as most of the heavy computational tasks are fully optimized for GPUs and that you don't want coal burning CPUs.
Even if it doesn't come in 5 year time-frame, there's a real threat and have to be ahead of time. After all, x86 already extended its life 10+ years when it could have been discontinued. Now it's really a dinosaur. If so, non-server applications would follow the route as well.
We want more simple / solid / robust base with scalability. Not an unreliable boost button that sometimes do the trick.
SystemsBuilder - Saturday, November 6, 2021 - link
I don't see AVX-512 that negatively it is just the same as AVX2 but double the vectors size and a with a richer instruction set. I find it pretty cool to work with especially when you've written some libraries that can take advantage of it. As I wrote before, it looks like Golden cove got AVX-512 right based on what Ian and Andrei uncovered. 0 negative offset (e.g. running at full speed), power consumption not much more than AVX2, and it supports both FP16 and BP16 vectors! I think that's pretty darn good! I can work with that! Now I want my Sapphire rapids with 32 or 48 Golden cove P cores! No not fall 2022 i want it now! lolmode_13h - Saturday, November 6, 2021 - link
> When you optimize code today (for pre Alder lake CPUs) to take advantage> of AVX-512 you need to write two paths (at least).
Ah, so your solution depends on application software changes, specifically requiring them to do more work. That's not viable for the timeframe of concern. And especially not if its successor is just going to add AVX-512 to the E-cores, within a year or so.
> There are many levels of AVX-512 support and effectively you need write customized
> code for each specific CPUID
But you don't expect the capabilities to change as a function of which thread is running, or within a program's lifetime! What you're proposing is very different. You're proposing to change the ABI. That's a big deal!
> It is absolutely possible and it will come with time.
Or not. ARM's SVE is a much better solution.
> I think in the future P and E cores might have more than just AVX-512 that is different
On Linux, using AMX will require a thread to "enable" it. This is a little like what you're talking about. AMX is a big feature, though, and unlike anything else. I don't expect to start having to enable every new ISA extension I want to use, or query how many hyperthreads actually support - this becomes a mess when you start dealing with different libraries that have these requirements and limitations.
Intel's solution isn't great, but it's understandable and it works. And, in spite of it, they still delivered a really nice-performing CPU. I think it's great if technically astute users have/retain the option to trade E-cores for AVX-512 (via BIOS), but I think it's kicking a hornets nest to go down the path of having a CPU with asymmetrical capabilities among its cores.
Hopefully, Raptor Lake just adds AVX-512 to the E-cores and we can just let this issue fade into the mists of time, like other missteps Intel & others have made.
SystemsBuilder - Saturday, November 6, 2021 - link
I too believe AVX-512 exclusion in the E cores it is transitory. next gen E cores may include it and the issue goes away for AVX-512 at least (Raptor Lake?). Still there will be other features that P have but E won't have so the scheduler needs to be adjusted for that. This will continue to evolve with every generation of E and P cores - because they are here to stay.I read somewhere a few months ago but right now i do not remember where (maybe on Anandtech not sure) that the AVX-512 transistor budget is quite small (someone measured it on the die) so not really a big issue in terms of area.
AMX is interesting because where AVX-512 are 512 bit vectors, AMX is making that 512x512 bit matrices or tiles as intel calls it. Reading the spec on AMX you have BF16 tiles which is awesome if you're into neural nets. Of course gpus will still perform better with matrix calculations (multiplications) but the benefit with AMX is that you can keep both the general CPU code and the matrix specific code inside the CPU and can mix the code seamlessly and that's gonna be very cool - you cut out the latency between GPU and CPU (and no special GPU API's are needed). but of course you can still use the GPU when needed (sometimes it maybe faster to just do a matrix- matrix add for instance just inside the CPU with the AMX tiles) - more flexibility.
Anyway, I do think we will run into a similar issue with AMX as we have the AVX-512 on Alder Lake and therefore again the scheduler needs to become aware of each cores capabilities and each piece of code need to state what type of core they prefer to run on: AVX2, AVX-512, AMX capable core etc (the compliers job). This way the scheduler can do the best job possible with every thread.
There will be some teething for a while but i think this is the direction it is going.
mode_13h - Sunday, November 7, 2021 - link
The difference is that AMX is new. It's also much more specialized, as you point out. But that means that they can place new hoops for code to jump through, in order to use it.It's very hard to put a cat like AVX-512 back in the bag.
SystemsBuilder - Saturday, November 6, 2021 - link
To be clear, I also want to add that the way code is written today (in my organization) pre Alder Lake code base. Every time we write a code path for AVX512 we need to write a fallback code path incase the CPU is not AVX-512 capable. This is standard (unless you can control the execution H/W 100% - i.e. the servers).Does not mean all code has to be duplicated but the inner loops where the 80%/20% rule (i.e. 20% of the code that consumes 80% of the time, which in my experience often becomes like the 99%/1% rule) comes into play that's where you write two code paths:
1 for AVX-512 in case it CPU is capable and
2 with just AVX2 in case CPU is not capable
mostly this ends up being just as I said the inner most loops, and there are excellent broadly available templates to use for this.
Just from a pure comp sci perspective it is quite interesting to vectorize code and see the benefits - pretty cool actually.