Imagination Launches Catapult Family of RISC-V CPU Cores: Breaking Into Heterogeneous SoCs
by Ryan Smith on December 6, 2021 11:00 AM EST- Posted in
- SoCs
- CPUs
- Imagination Technologies
- RISC-V
- Catapult
December is here, and with it comes several technical summits ahead of the holiday break. The most notable of which this week is the annual RISC-V summit, which is being put on by the Linux Foundation and sees the numerous (and ever increasing) parties involved in the open source ISA gather to talk about the latest products and advancements in the RISC-V ecosystem. The summit always tends to feature some new product announcements, and this year is no different, as Imagination Technologies is at the show to provide details on their first RISC-V CPU cores, along with announcing their intentions to develop a full suite of CPU cores over the next few years.
The company, currently best known for their PowerVR GPU lineup, has been dipping their toes into the RISC-V ecosystem for the last couple of years with projects like RVfpga. More recently, this past summer the company revealed in an earnings call that they would be designing RISC-V CPU cores, with more details to come. Now at the RISC-V summit they’re providing those details and more, with the formal announcement of their Catapult family of RISC-V cores, as well as outlining a heterogeneous computing-centric roadmap for future development.
Starting from the top, the Catapult family is Imagination’s overarching name for a complete family of RISC-V CPU cores, the first of which are launching today. Imagination has (and is) designing multiple microarchitectures in order to cover a broad range of performance/power/area (PPA) needs, and the Catapult family is slated to encompass everything from microcontroller-grade processors to high-performance application processors. All told, Imagination’s plans for the fully fleshed out Catapult family look a lot like Arm’s Cortex family, with Imagination preparing CPU core designs for microcontrollers (Cortex-M), real-time CPUs (Cortex-R), high performance application processors (Cortex-A), and functionally safe CPUs (Cortex-AE). Arm remains the player to beat in this space, so having a similar product structure should help Imagination smooth the transition for any clients that opt to disembark for Catapult.

At present, Imagination has finished their first CPU core design, which is a simple, in-order core for 32-bit and 64-bit systems. The in-order Catapult core is being used for microcontrollers as well as real-time CPUs, and according to the company, Catapult microcontrollers are already shipping in silicon as part of automotive products. Meanwhile the real-time core is available to customers as well, though it’s not yet in any shipping silicon.
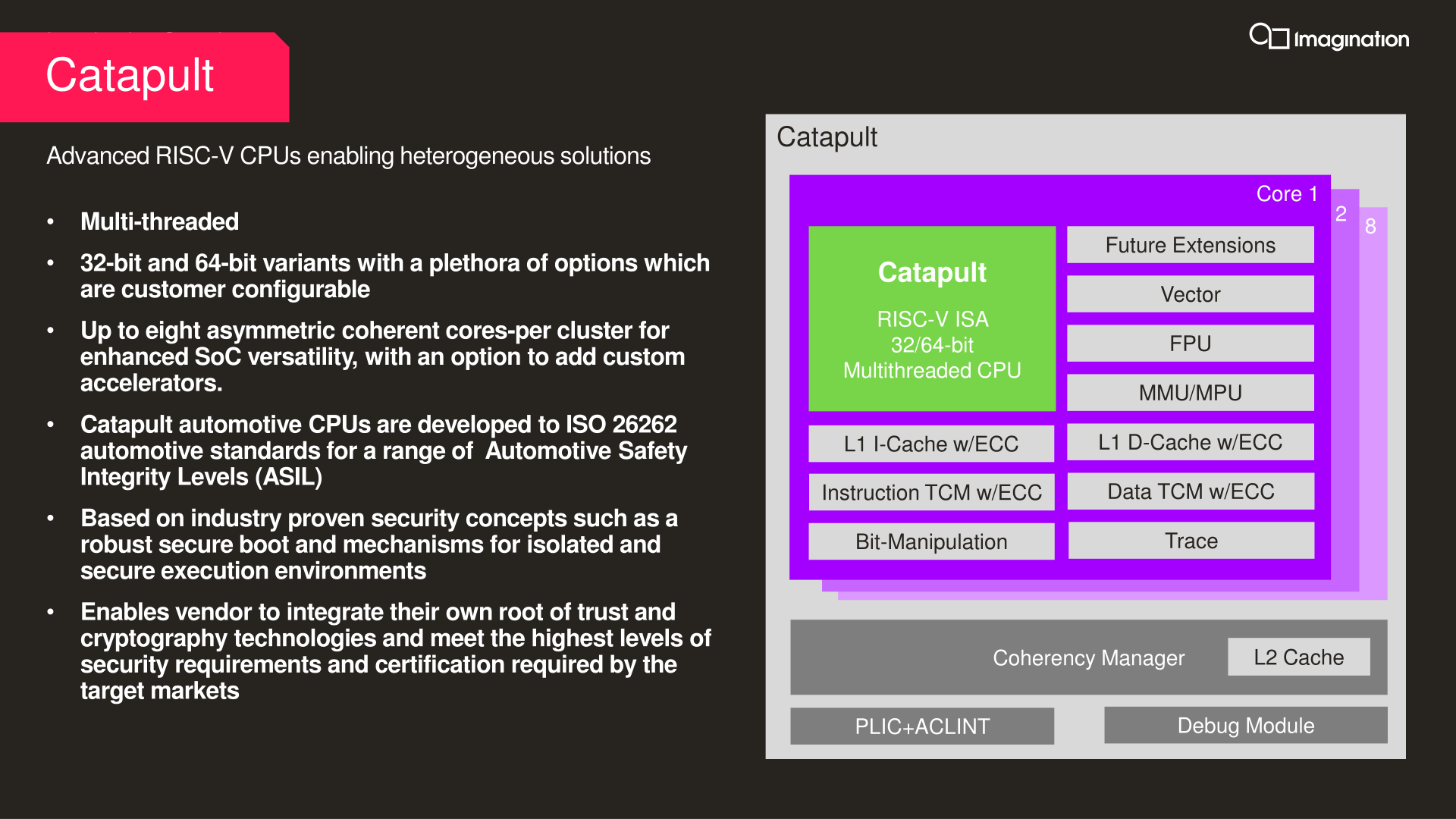
The current in-order core design supports up to 8 cores in a single cluster. The company didn’t quote any performance figures, though bear in mind this is a simple processor meant for microcontrollers and other very low power devices. Meanwhile, the core is available with ECC across both its L1 and TCM caches, as well as support for some of RISC-V’s brand-new extensions, such as the Vector computing extension, and potentially other extensions should customers ask for them.
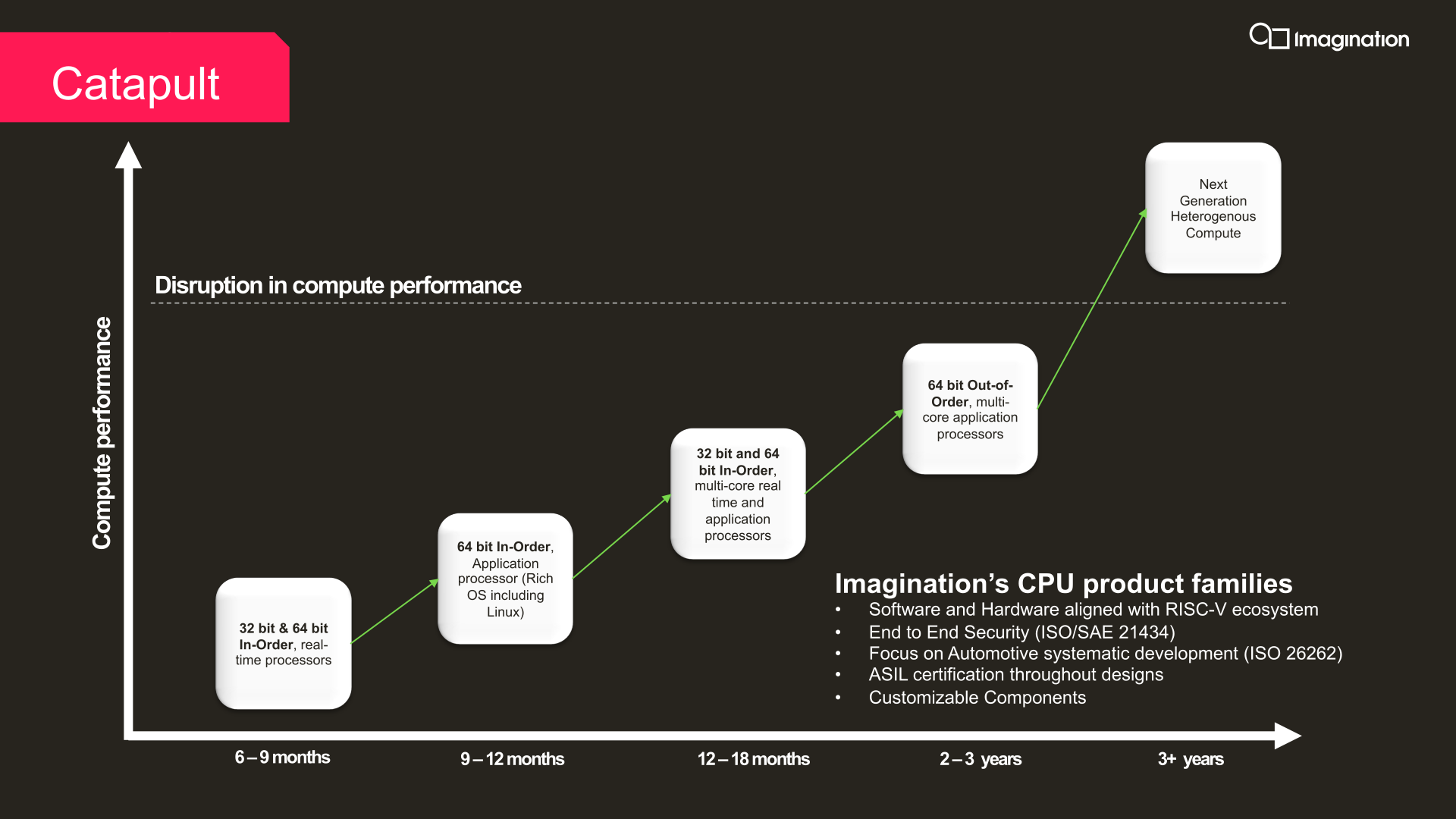
Following the current in-order core, Imagination has essentially three more core designs on their immediate roadmap. For 2022 the company is planning to release an enhanced version of the in-order core as an application processor-grade design, complete with support for “rich” OSes like Linux. And in 2023 that will be followed by another, even higher performing in-order core for the real-time and application processor markets. Finally, the company is also developing a much more complex out-of-order RISC-V core design as well, which is expected in the 2023-2024 timeframe. The out-of-order Catapult would essentially be their first take on delivering a high-performance RISC-V application processor, and like we currently see with high-performance cores the Arm space, has the potential to become the most visible member of the Catapult family.
Farther out still are the company’s plans for “next generation heterogeneous compute” designs. These would be CPU designs that go beyond current heterogeneous offerings – namely, just placing CPU, GPU, and NPU blocks within a single SoC – by more deeply combining these technologies. At this point Imagination isn’t saying much more, but they are making it clear that they aren’t just going to stop with a fast CPU core.
Overall, these are all clean room designs for Imagination. While the company has long since sold off its Meta and MIPS CPU divisions, it still retains a lot of the engineering talent from those efforts – along with ownership of or access to a large number of patents from the area. So although they aren’t reusing anything directly from earlier designs, they are hoping to leverage their previous experience to build better IP sooner.
Of course, CPU cores are just one part of what it will take to succeed in the IP space; besides incumbent Arm, there are also multiple other players in the RISC-V space, such as SiFive, who are all vying for much of the same market. So Imagination needs to both differentiate themselves from the competition, and offer some kind of market edge to customers.

To that end, Imagination is going to be heavily promoting the possibilities for heterogenous computing designs with their IP. Compared to some of the other RISC-V CPU core vendors, Imagination already has well-established GPU and NPU IP, so customers looking to put together something more than just a straight CPU will be able to tap into Imagination’s larger library of IP. This does put the company more in direct competition with Arm (who already has all of these things as well), but then that very much seems to be Imagination’s goal here.

Otherwise, Imagination believes that their other big advantage in this space is the company’s history and location. As previously mentioned, Imagination holds access to a significant number of patents; so for clients who want to avoid extra patent licensing, they can take advantage of the fact that Imagination’s IP already comes indemnified against those patents. Meanwhile for chip designers who are based outside of the US and are weary of geopolitical issues affecting ongoing access to IP, Imagination is naturally positioned as an alternative there since they aren’t based in the US either – and thus access to their IP can’t be cut off by the US.

Wrapping things up, with the launch of their Catapult family of RISC-V CPU IP, imagination is laying out a fairly ambitious plan for the company for the next few years. By leveraging both their previous experience building CPUs as well as their current complementary IP like GPUs and NPUs, Imagination has their sights set on becoming a major player in the RISC-V IP space – and particularly when it comes to heterogeneous compute. Ultimately a lot will need to go right for the company before they can get there, but if they can succeed, then with their diverse collection of IP they would be in a rather unique position among RISC-V vendors.





Source: Imagination Technologies








62 Comments
View All Comments
mode_13h - Saturday, December 11, 2021 - link
> Apple small cores are OoO and they are the most efficient right now.It's not quick or easy to make them that efficient.
Also, you're only looking at efficiency in terms of perf/W. There are other metrics that count, such as area-efficiency, which roughly translates into perf/$.
Making an OoO core as fast and efficient as Apple's uses quite a lot more transistors, which could blow the price targets for whatever applications Imagination has in mind. Think embedded, IoT-style uses, which tend to be very cost-sensitive.
Kangal - Sunday, December 12, 2021 - link
You're right, but Apple has always envisioned and strived for innovation in performance, power, and area. Apple's small cores are actually not that large, but they are low-power, and have lots of performance on-tap. ARM will possibly follow in their lead, by designing a better low-power core for the industry; Qualcomm, Samsung, HiSilicon, MediaTek, RockChip, Unisoc, Allwinner, AMLogic, etc etc.Talking about Huawei.... was it not that ImaginationTechnologies (UK company) had a hostile take-over by a Chinese firm? Well, there have been a lot of senior engineers who ended up leaving the company. Some direct to Apple, others into other industries. So I think Anandtech is wrong here, they don't have the talent, but they sure do have the IP.
They are more than likely being pumped with cash to get these solutions out there, via State Subsidies like Huawei has. So they have the IP, and now they have the money, they have RISC-V as a CPU, there is SIMC lithography, Huawei can build the micro-modem, and lastly they have the open-source software such as JingOS. So all the necessary parts are there to build a fully functioning SoC for the Chinese market, without interferences from USA.
So if they continue on this path, they will achieve a SoC equivalent to the QSD 835 in the next 3 years. Probably equivalent to the Cortex-A73, on a 16nm node, with JingOS or similar software. And going further, after 5 years they will possibly match the likes of the QSD 888. That seems like a lifetime away in the tech industry. But another way of looking at it, is that it is Rapid Innovation, since they are almost starting from scratch.
dotjaz - Sunday, January 2, 2022 - link
Maybe you are too dumb to understand OOO can't do sub-100mW. Where's the efficiency ?dotjaz - Friday, December 10, 2021 - link
How do you justify the inefficiency and big die areas? One OOO core would be as big as 6-8 in-order cores especially stripped down microcontrolller cores. And it's not even matching the performance.OOO design has awful performance density and also much worse efficiency at sub 1GHz mark, end of the story.
And you want justification? Simple, packet processors. You need dirt cheap parallel processing power. OOS is simply useless.
mode_13h - Friday, December 10, 2021 - link
simply nailed it: )
Oxford Guy - Monday, December 27, 2021 - link
Yes, obviously Apple doesn't know what it's doing.mode_13h - Monday, December 6, 2021 - link
If your workload has enough concurrency (i.e. can be split up across enough threads), then having a large number of in-order cores is a far more area-efficient and power-efficient way to scale performance. This is exactly what GPUs do.Oxford Guy - Tuesday, December 7, 2021 - link
Then why not a GPU?mode_13h - Wednesday, December 8, 2021 - link
GPUs tend to have wide SIMD units and many-way SMT. If your code involves mostly scalar computations, then the SIMD registers + pipeline(s) are a waste of die space.As for SMT, each thread requires its own copy of architectural state, which means more registers and other structures (e.g. additional tags in things like caches and branch-predictors). They could certainly go SMT with these cores, as discussed below, but likely not to the same extent as GPUs.
Lastly, GPU ISAs tend to lack critical features and instructions needed to run a modern OS. Often, GPUs can't even do instruction-level traps. If you added some of those things to a GPU, they'd add overhead, making it less efficient at its main task.
It's a bit like asking why you can't use a chainsaw to carve a turkey. Both a chainsaw and a carving knife are sharp and made for cutting, but the chainsaw wouldn't be terribly "efficient" with the meat, while burning a lot of power and making a lot of noise.
CPU_junkie - Wednesday, December 8, 2021 - link
simply nailed it