Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
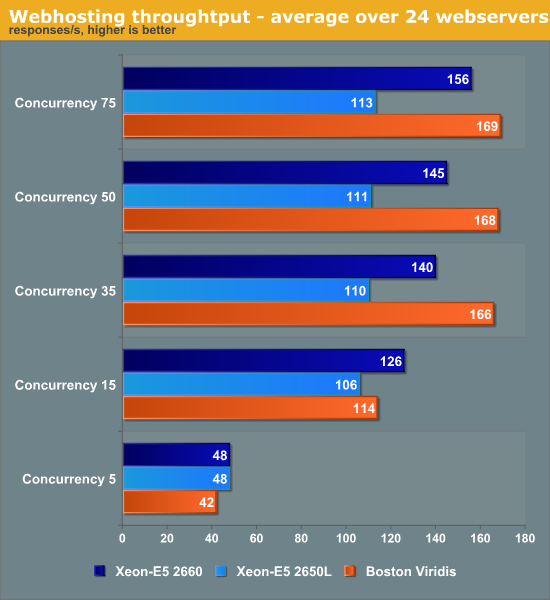
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
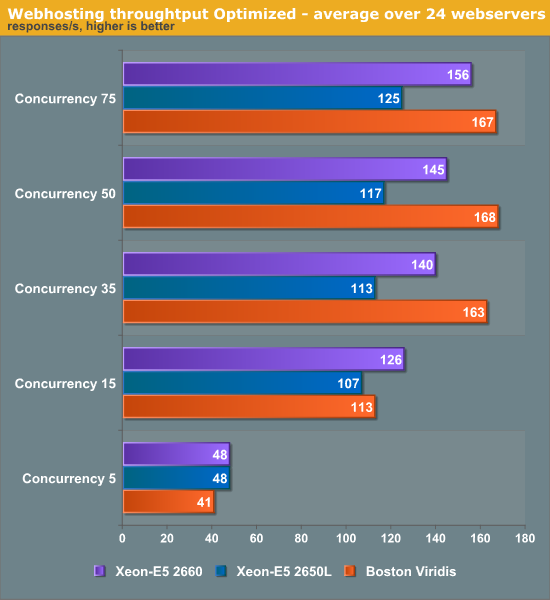
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
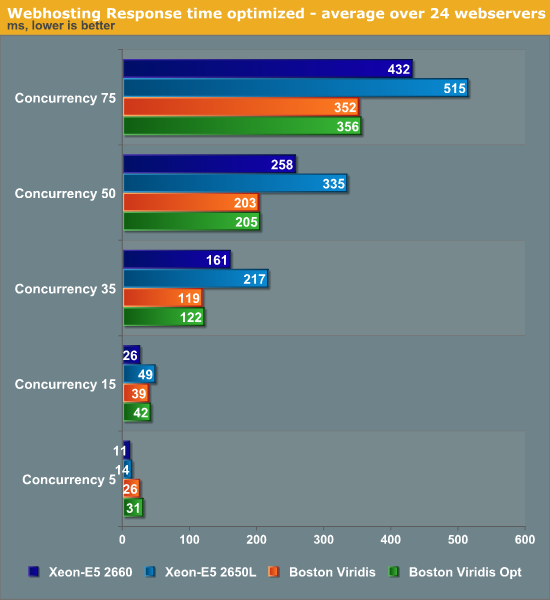
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.








99 Comments
View All Comments
Kurge - Wednesday, March 13, 2013 - link
Yeah, should have had two teams - each with goal to optimize on each platform. The Xeon team would not (lol) load up 24 VM's to serve the same web app. It's silly. Go bare metal in that use case.There will be different needs for different cases. The "lets load up a bunch of VMs" is useful to cloud providers and in other cases, but not for "I want to feed this app to as many users as possible".
dig23 - Tuesday, March 12, 2013 - link
Interesting article and great first effort but felt bit outdated on both ATOM as well as ARM front, I am not blaming you, just saying.JarredWalton - Tuesday, March 12, 2013 - link
Outdated in what sense? No one else has really made a serious attempt to review thee Calxedas stuff, and while there are better Atom option out there, as Johan notes we were unable to get any in-house in time for testing. Or do you mean Calxedas' use of Cortex-A9 is outdated? If so, that's more of a case of laying the groundwork I think. Assuming they have their A15 option be backwards compatible with the current system (e.g. just get a new set of cards with the updated SoCs), that would be very cool.JohanAnandtech - Wednesday, March 13, 2013 - link
I can only agree with Jarred. There are no A15 server chips AFAIK, and unless I have missed a launch, I think the Atom N2800 is not outdated at all (Dec 2011).aryonoco - Wednesday, March 13, 2013 - link
This was a fabulous and most informative write up. You answered so many of my questions with this article. Excellent job covering an area that no one else is, and also kudos for running such great benchmarks.This really is tech journalism at its best. Thank you Johan, and thank you Anand for employing such high-quality writers.
We all know how memory constrained the ARM A9 is. Even something like Krait would solve a lot of A9's traditional weak areas. And yet, it looks like the Calxeda makes sense in enough niches to be sustain their R&D and development efforts. Low-to-medium traffic web hosting, media streaming and storage. Each one of those areas is a sizeable market and the Calxeda solution offers enough to be seriously considered in these makets.
And when one thinks about how many years of x86 optimisation has gone into the toolchain in things like the gcc, one realises the potential that lies ahead for ARM in this market. ARM's future roadmap is well known, next is Cortex A15 and then Cortex A57. Meanwhile there will be more software optimisation, and the management/deployment side will also improve. With all these in mind, I think it's more than conceivable that ARM will grab up to 20% marketshare in the server market by 2015.
JohanAnandtech - Wednesday, March 13, 2013 - link
Thanks! Good summary... and indeed 20% marketshare is not impossible. The real questions is whether Intel give the Atom it is long overdue architecture update, or will Haswell put some pressure from above? Exciting times.beginner99 - Wednesday, March 13, 2013 - link
Isn't it much easier to administer 24 virtual servers than 24 physical ones (cost of personnel)? When all servers have the same workload it look sgood for ARM but the virtualized intel environment easily wins if some servers get a lot more requests than others, meaning too much for one ARM SOC to handle. The tested scenario is basically the best one could ever hope for the ARM server and pretty unrealistic (same load for all servers). That's fine but then also post worst-case scenarios...Intel server is a lot more flexible.hardwaremister - Wednesday, March 13, 2013 - link
I completely agree with the other readers that this writing is just absolutely superb. Fantastic novel job Johan.However, I also agree with the above commenter: a big part coup on virtualizing a "fat" core system is to be able to properly utilize the resources of the machine across VMs. By equally loading "tiny tiles", the obvious advantage of the inherent load balancing of a virtualized infrastructure completely disappears.
Under current the current "fat" VM infrastructure you can accomodate individual VMs with heterogeneous loading levels, with extra provisioning in the resource pool.
That is just not simply the case for these tests based on an army of individual machines against a many VMs virtualized under a few "fat" cpus.
I don't mean to be overcritical, but this is a proper apples vs oranges comparison.
bobbozzo - Wednesday, March 13, 2013 - link
A lot of shared hosting ISP's use lightweight virtualization with Linux or BSD "Containers". I would like to see you re-benchmark with those on both servers instead of using VMs.You should see higher performance vs full virtualization. I'm not sure how it would affect the ARM performance, but it shouldn't hurt much, and there is more potential for better load sharing if some sites are busier than others.
Jambe - Wednesday, March 13, 2013 - link
Surprising, indeed! Thoroughgoing as usual, and excellently written.