Google Announces AMD Milan-based Cloud Instances - Out with SMT vCPUs?
by Andrei Frumusanu on June 17, 2021 11:00 AM EST- Posted in
- CPUs
- AMD
- Enterprise
- AWS
- Azure
- Milan
- Google Compute Cloud
Today, Google announced the planned introduction of their new set of “Tau” VMs, or T2D, in their Google Compute Engine VM offerings. The hardware consists of AMD’s new Milan processors – which is a welcome addition to Google’s offerings.
The biggest news of today’s announcement however was not Milan, but the fact of what Google is doing in terms of vCPUs, how this impacts performance, and the consequences it has in the cloud provider space – particularly in context of the new Arm server CPU competition.

Starting off with the most important data-point Google is presenting today, is that the new GCP Tau VMs showcase a staggering performance advantage over the competitor offerings from AWS and Azure. The comparison VM details are published here:
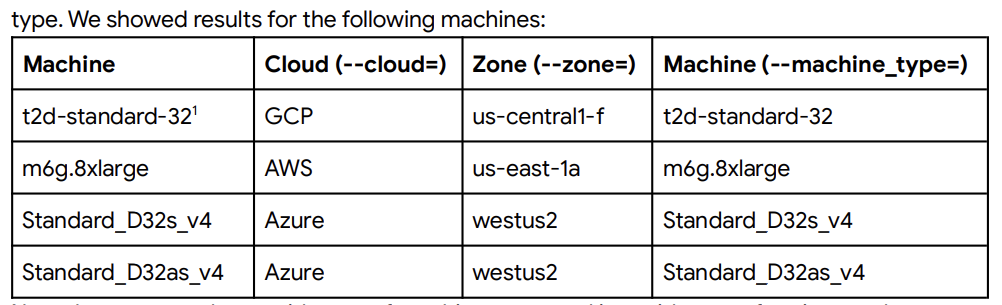
Google’s SPECrate2017_int methodology largely mimics our own internal usage of the test suite in terms of flags (A few differences like LTO and allocator linkage), but the most important figure comes down from the disclosure of the compilers, with Google stating that the +56% performance advantage over AWS’s Graviton2 comes from an AOCC run. They further disclose that a GCC run achieving a +25% performance advantage, which clarifies some aspects:
Note that we also tested with GCC using -O3, but we saw better performance with -Ofast on all machines tested. An interesting note is that while we saw a 56% estimated SPECrate®2017_int_base performance uplift on the t2d-standard-32 over the m6g.8xlarge when we used AMD's optimizing compiler, which could take advantage of the AMD architecture, we also saw a 25% performance uplift on the t2d-standard-32 over the m6g.8xlarge when using GCC 11.1 with the above flags for both machines.
Having this 25% figure in mind, we can fall back to our own internally tested data of the Graviton2 as well as the more recently tested AMD Milan flagship for a rough positioning of where things stand:
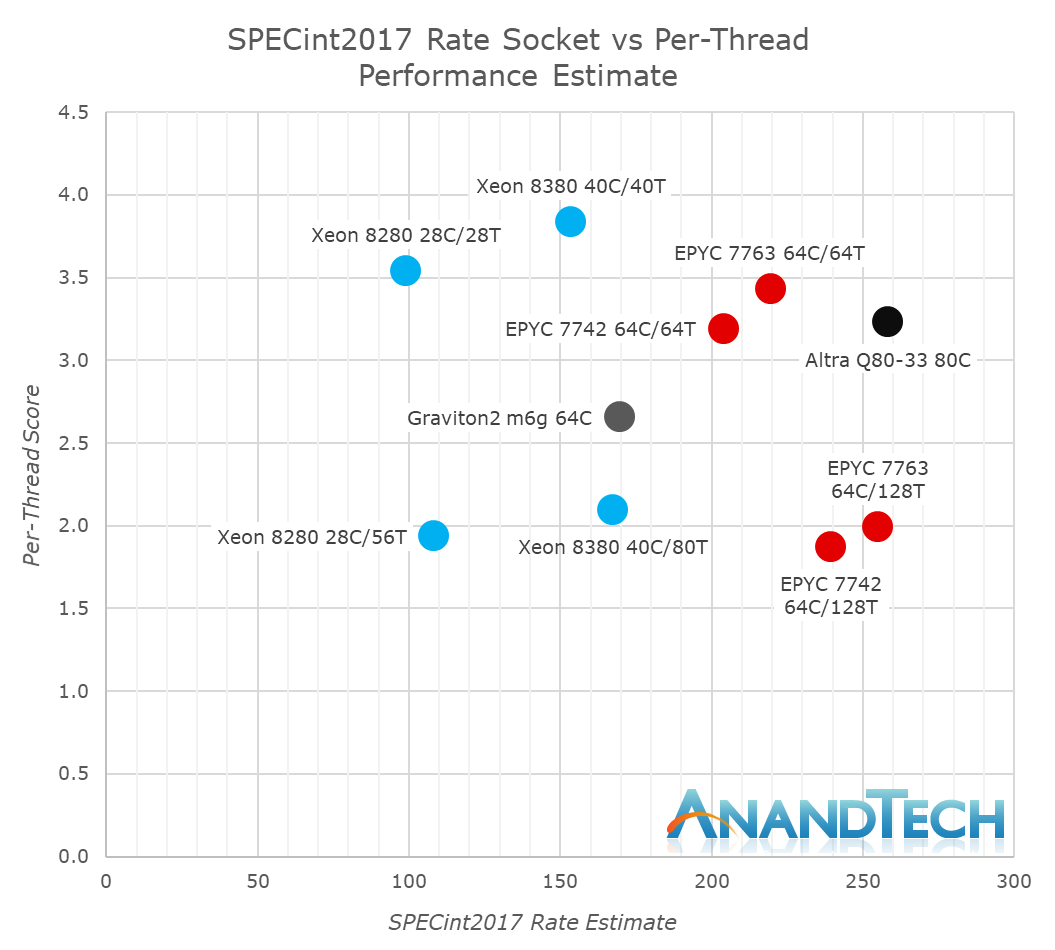
Google doesn’t disclose any details of what kind of SKU they are testing, however we do have 64-core and 32-core vCPU data on Graviton2, scoring estimated scores of 169.9 and 97.8 with per-thread scores of 2.65 and 2.16. Our internal numbers of an AMD EPYC 7763 (64 core 280W) CPU showcase an estimated score of 255 rate and 1.99 per thread with SMT, and 219 rate and 3.43 per thread for respectively 128 threads and 64 thread runs per socket. Scaling the scores down based on a thread count of 32 – based on what Google states here as vCPUs for the T2D instance, would get us to scores of either 63.8 with SMT, or 109.8 without SMT. The SMT run with 32 threads would be notably underperforming the Graviton2, however the non-SMT run would be +12 higher performance. We estimate that the actual scores in a 32-vCPU environment with less load on the rest of the SoC would be notably higher, and this would roughly match up with the company’s quoted +25 performance advantage.
And here lies the big surprise of today’s announcement: for Google's new Milan performance figures to make sense, it must mean that they are using instances with vCPU counts that actually match the physical core count – which has large implications on benchmarking and performance comparisons between instances of an equal vCPU count.
Notably, because Google is focusing on the Graviton2 comparison at AWS, I see this as a direct attack and response to Amazon’s and Arm’s cloud performance metric claims in regards to VMs with a given number of vCPUs. Indeed, even when we reviewed the Graviton2 last year, we made note of this discrepancy that when comparing cloud VM offerings to x86 cloud offerings which have SMT, and where a vCPU essentially just means you’re getting a logical core instead of a physical core, in contrast to the newer Arm-based Graviton2 instances. In effect, we had been benchmarking Arm CPUs with double the core counts vs the x86 incumbents at the same instance sizes. Actually, this is still what Google is doing today when comparing a 32vCPU Milan Tau VM against a Azure 32vCPU Cascade Lake VM – it’s a 32 core vs 16 core comparison, just the latter has SMT enabled.
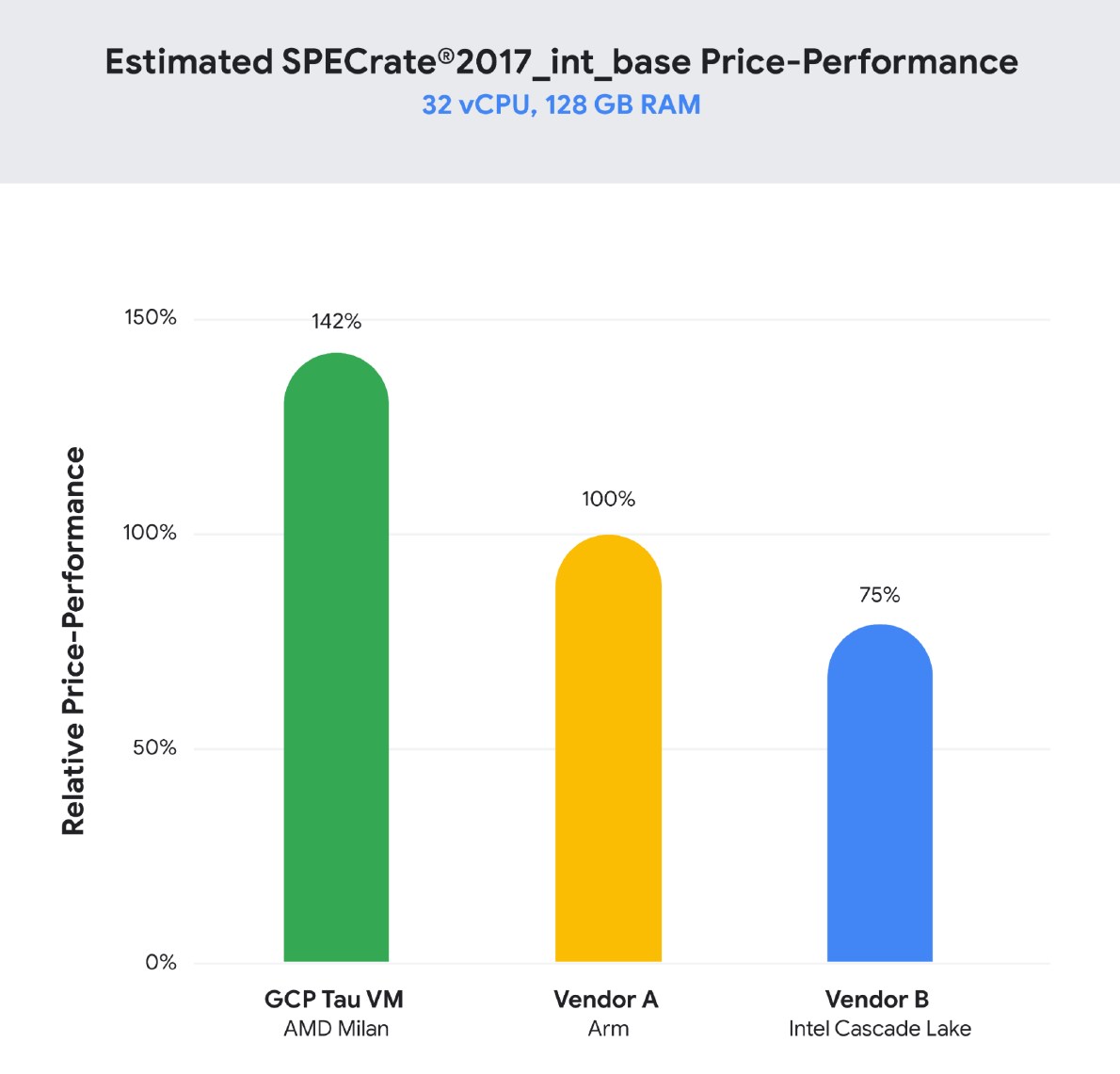
Because Google is now essentially levelling the playing field against the Arm-based Graviton2 VM instances at equal vCPU count, by actually having the same number of physical cores available, it means that it has no issues to compete in terms of performance with the Arm competitor, and naturally it also outperforms other cloud provider options where a vCPU is still only a logical SMT CPU.
Google is offering a 32vCPU T2D instance with 128GB of RAM at USD 1.35 per hour, compared to a comparable AWS instance of m6g.8xlarge with also 32vCPUs and 128GB of RAM at USD 1.23 per hour. While Google’s usage of AOCC to get to the higher performance figures compared to our GCC numbers play some role, and Milan’s performance is great, it’s really the fact that we seem to now be comparing physical cores to physical cores that really makes the new Tau VM instances special compared to the AWS and Azure offerings (physical to logical in the latter case).
In general, I applaud Google for the initiative here, as being offered only part of a core as a vCPU until now was a complete rip-off. In a sense, we also have to thank the new Arm competition in finally moving the ecosystem into bringing about what appears to be the beginning of the end of such questionable vCPU practices and VM offerings. It also wouldn’t have been possible without AMD’s new large core count CPU offerings. It will be interesting to see how AWS and Azure will respond in the future, as I feel Google is up-ending the cloud market in terms of pricing and value.








24 Comments
View All Comments
kepstin - Thursday, June 17, 2021 - link
I wonder if a part of this was due to security concerns with hyperthreading, and the performance numbers were just a bonus that they decided to use as a way to promote the change.Amazon has made sure that all current instance types always get pairs of hyperthreads on the same core, but lets you configure whether or not you actually want hyperthreading enabled based on whether you have cross-process security concerns with your particular application (and software licensing per vcpu costs, too).
I worker if Google has just decided "you know what? no more hyperthreads." rather than make it configurable, or because they didn't think people would pick the right option.
DanNeely - Thursday, June 17, 2021 - link
This really sounds and feels like smoke and mirrors wrapped around a price cut.Most workloads will show higher throughput/physical core from running 2 threads at a time in SMT, and for most workloads overall throughput matters more than the time to process individual responses.
If they're winning price/perf vs an equivalent SMT system by pricing the individual cores cheaper it's the lower price getting them the win and the same cores would offer more performance if SMT was turned on.
And especially on smaller servers I'd rather have 1 or 2 physical cores with SMT on than 1 or 2 cores with SMT off because the extra threads help a lot with hiding the impact of an admin running a compute heavy report that hogs a thread for 30 seconds or several minutes from other users.
Andrei Frumusanu - Thursday, June 17, 2021 - link
At the end of the day the rationale doesn't matter as the price and value is competing, and that's where the huge leap lies in.DanNeely - Thursday, June 17, 2021 - link
The actual value is all in Epyc sold cheap. But most customers would benefit more from a N(2N) core SMT VM than an N core non-SMT one. Offering the ability to turn SMT off for customers willing to pay a premium for low response time is a nice value add; but shouldn't be the default/primary configuration.name99 - Thursday, June 17, 2021 - link
Are you SURE about that "most customers would benefit more from a N(2N) core SMT VM than an N core non-SMT one"?Clearly there are *some* workloads for which this is true, but the weights to associate with these (number of customers; importance they place on the workload) are far from obvious...
There ARE two data points that we know about:
- anything HPC-like (so using vectors basically every cycle) gains essentially zero from SMT
- anything that's mainly moving memory around and so bandwidth limited gains essentially zero from SMT. Dick Sites, in his very interesting talk about what he (and, in a sense Google) want from future CPUs/data center SoCs makes a big deal of this, that the main thing he wants is the ability (with a duty cycle of 25%) to move 16B per cycle, assuming it's going to miss in RAM.
Interestingly Apple M1 delivers this today (kinda -- ~20B/cycle, which you can either say is better than required [using only performance cores] or right on the edge [considering an E core as quarter of a performance core]), but of course Apple is not in the data warehouse space. No-one else comes close.
So point is, there are two clear use cases for these warehouse scale machines that don't benefit from SMT. Obviously there are other things that such a machine can do, and the primary win of SMT is optionality; if you can exploit that optionality by scheduling FP-heavy (but memory light) code code alongside memory heavy or int heavy code, you can have a win. But that requires your scheduler to track this info (by CPU counters I guess) and that you have an even enough pool of complementary tasks.
For that you pay at least some extra gate delays and endless security issues. Is it a good tradeoff compared to other alternatives (eg use either large cores or small cores, small cores handling memory-heavy stuff; or share rarely-used vector hardware between two cores)? My guess is not; it was a bad idea that has been allowed to survive for far too long.
nevcairiel - Thursday, June 17, 2021 - link
Of course the real difference is not in 2 cores without SMT, or 2 cores with SMT, its 2 real cores, or 2 "virtual" cores (or 1 with SMT, if you will)Of course you could just say to buy twice as many of the virtual cores, but that is where pricing makes the big impact. And in marketing, or any third-party comparison, these real cores will always shine, and if they are priced competitively against other offerings with virtual SMT cores, who is to complain?
yannigr2 - Thursday, June 17, 2021 - link
I don't know what is more shocking here. AMD having that much of an advantage, or Intel being so far behind.kgardas - Friday, June 18, 2021 - link
In fact it's other way around. Intel is running with half the cores and yet being able to nearly reach half of AMD performance. That's what's shocking. And even more is that google is comparing previous generation (Intel) with current (AMD).Spunjji - Friday, June 18, 2021 - link
Last I knew, Intel's current gen still isn't widely available. It seems to be roughly where Milan was back in January.RSAUser - Wednesday, June 30, 2021 - link
Erm, there are no competitive 64C Intel parts, they are pretty much dual socket chips which makes them noncompetitive in terms of pricing. Their 32C Ice Lake clocks are only similar to the AMD 7713P (their "cheap" $k 64C/128T part) while AMD's side is a bit better in IPC.Intel is currently not that competitive, their biggest advantage right now is lots of software they've made that is designed for their CPU's, I do hope they make a comeback sooner rather than later so AMD doesn't get complacent.