Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
EPIC 101
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
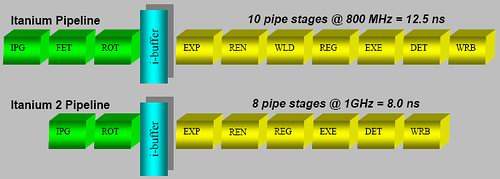
The short Itanium and Itanium 2 pipeline
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.

IA-64 instruction bundle
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
Compare R1 to 0 (IF...)You get:
If false jump to Label
R2 =R3 ("Then" instructions)
Label: (Else instructions)
R2 =R1
On the condition that R=0, R2=R3So you eliminate the conditional jump ("If false, jump to") and replace the whole "IF THEN ELSE" clause with an instruction that checks the register and then moves the contents from R3 to R2 in one sweep. Conditional jumps are dependant on the instruction before it and they have to wait until the "Compare R1 to 0" instruction is done. Conditional instructions, however, travel through the pipeline for execution and don't have to wait for anything. You could say that the "IF" part and "Then" part are fused together. For the "else" part, you get:
On the condition that R<>0, R2 = R1Predication makes the code more compact, and eliminates branches and dependencies. Branches can make up 20% of your code, easily. So, with one branch every 5 instructions, it is very hard to issue many instructions in parallel. By converting them into conditional instructions, you eliminate the dependencies and the ILP can get much higher.
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
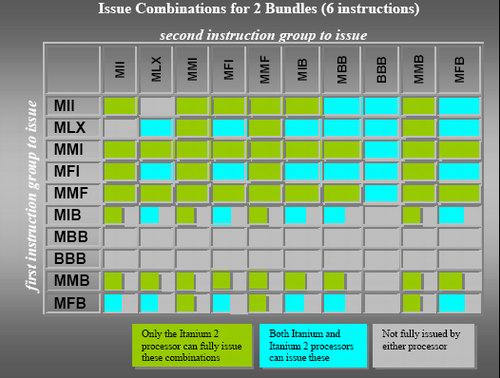
Possible bundles
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
- Easy decoding leads to a shorter pipeline as less decoding work has to be done, so less stages are necessary;
- In order issue and execution means that dispatch hardware is much simpler, which leads to a shorter pipeline and less transistors;
- Removing conditional jumps and letting the compiler do the scheduling extracts more ILP; and
- 128 registers and the load/store model reduce the number of memory/cache accesses significantly,
- No out-of-order execution makes cache misses and pipelines stalls much more costly; and
- 128 registers and the whole bundle and group system make the instructions on average much longer than x86.








43 Comments
View All Comments
ravedave - Thursday, November 10, 2005 - link
Who cares about TLP in the consumer space? Nothign can take advantage of it, HT showed that. I think whoever comes out with the best individual core next will do some sweet buisiness...eastvillager - Thursday, November 10, 2005 - link
That train is Opteron. All aboard!Itanium had a window where it could've shown, Intel missed it by a mile. Well, on the bright side, they killed HP's Unix Server business at the same time. I remember when HP announced they were stopping r&d on new PA-RISC processors and were switching to Itanium.
ElFenix - Thursday, November 10, 2005 - link
the story of how intel killed it for a processor that was about a a decade and a half, if not more, ahead of its time? and mostly because it wasn't invented at intel, but rather was bought as part of the dec compaq hp debacle (ooo, inept management again!). that was about the most promising processor on the planet for a while, but now its buried.Zebo - Thursday, November 10, 2005 - link
Wow Johan I don't even care about Itanium but your prose kept me all the way through. :) Excellent write up.WhoBeDaPlaya - Wednesday, November 9, 2005 - link
Interesting read, especially after having just talked with two engineers from the Itanium team (they were from the HP side) at Fort Collins. *Keeping fingers crossed for career prospects there* :DMatthias - Wednesday, November 9, 2005 - link
"The Itanium is also wider than the competition, which results in bigger benefits from threading techniques."I don't buy that. Current Montecito's implementation of TLP only uses "Switch-on-Event Multithreading" which is a another name for Course Grain MT. At any specific time there is only one thread being executed per Montecito core. How can then a wider cpu benefit more than a more narrow cpu? You cannot use the unused execution units with instruction from another thread. So, where is the advantage of having more execution units available?
The multithreading approach in Montecito helps hiding latencies but not doing more in parallel. You can't execute two instructions from different threads at the same time! The P4 can do so, although its capabilities in parallel instruction execution is limited by its rather narrow design.
Of course, we are talking about one specific EPIC implementation. Nobody can't guarantee that with the next EPIC microarchitecture there will be an SMT in favor of a SoE-MT implementation. In this case the above statement would be correct, although I doubt that we will ever see an SMT implementation for Itanium. The static instruction issue used in Itanium does not fit very well with the rather dynamic issuing introduced with SMT.
IntelUser2000 - Wednesday, November 9, 2005 - link
SoEMT hides memory latency, which is in a way taking advantage of increased ILP Itanium has since memory latency may limit the benefit.Also, it seems the performance among various apps vary as MUCH as opinions about the chip vary :). Some people really like it, while some hate it.
About the performance, I can't find the link. There was an IDF presentation on PC World(found by google) and showed relative Montecito performance. It was around 20% faster per clock in integer, but they were very ambiguous about it. Citing MT, higher frequency, more cache, and dual cores. But for all that, 20% is so little. There was another IDF presentation about Foxton Technology, and showed Montecito benchmarks on TPC-C, which from numbers was almost 25% faster at same clock, half the sockets(same number of cores) and same platform.
Intel and HP usually introduce better compilers at the same time, so I think its reasonable to expect 20-25% per clock. One other significant improvement on Montecito will be that it will have another shift unit, making the total two, along with others like more instructions and some little improvements here and there.
Montecito has x86 compatibility unit taken out, using the software based IA32-EL.
IntelUser2000 - Wednesday, November 9, 2005 - link
Itanium 2 Madison cache latency:32KB L1: 1 cycle
256KB L2: 6 cycles
9MB L3: 14 cycles
Montecito:
32KB L1: 1 cycle
1MB L2I, and 256KB L2D: 6 cycles(same as Madison)
24MB L3: 14 cycles(same as madison)
stephenbrooks - Wednesday, November 9, 2005 - link
I like this bit.--[HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 transistors,]--
fic - Wednesday, November 9, 2005 - link
http://www.pasemi.com/">http://www.pasemi.com/These are PowerPC chips, but not from IBM. From the website: "dual-core device, operates at 2GHz with typical power dissipation in the range of 5 to 13 watts". According to articles SPECint is >1000 per core and SPECfp >2000 per core.